Requirements Specification
This document contains the Requirements Specification for the Libre RISC-V micro-architectural design. It shall meet the target of 5-6 32-bit GFLOPs, 150 M-Pixels/sec, 30 Million Triangles/sec, and minimum video decode capability of 720p @ 30fps to a 1920x1080 framebuffer, in under 2.5 watts at an 800mhz clock rate. Exceeding this target is acceptable if the power budget is not exceeded. Exceeding this target "just because we can" is also acceptable, as long as it does not disrupt meeting the minimum performance and power requirements.
General Architectural Design Principle
The general design base is to utilise an augmented and enhanced variant of the original CDC 6600 scoreboard system. It is not well-known that the 6600 includes operand forwarding and register renaming. Precise exceptions, precise in-order commit, branch speculation, "nameless" registers (results detected that need not be written because they have been overwritten by another instruction), predication and vectorisation will all be added by overloading write hazards.
An overview of the design is as follows:
- 3D and Video primitives (operations) will only be added as strictly necessary to achieve the minimum power and performance target.
- Identified so far is a 4xFP32 ARGB Quad to 1xINT32 ARGB pixel conversion opcode (part of the Vulkan API). It will write directly to a separate "tile buffer" (SRAM), not to the integer register file. The instruction will be scalar and will inherently and automatically parallelised by SV, just like all other scalar opcodes.
- xBitManip opcodes will be required to deal with VPU workloads
- The register files will be stratified into 4-way 2R1W banks, with separate and distinct byte-level write-enable lines on all four bytes of all four banks.
- 6600-style scoreboards will be augmented with "shadow" wires and write hazard capability on exceptions, branch speculation, LD/ST and predication.
- Each "shadow" capability of each type will be provided by a separate Function Unit. For example if there is to exist the possibility of rolling ahead through two speculative branches, then two separate Branch-speculative Function Units will be required: each will hold their own separate and distinct "shadow" (Go-Die wire) and write-hazard over instructions on which the branch depends.
- Likewise for predication, which shall place a "hold" on the Function Units that depend on it until the register used as a predicate mask has been read and decoded, there will be separate Function Units waiting for each predication mask register. Bits in the mask that are "zero" will result in "Go-Die" signals being sent to the Function Units previously (speculatively) allocated for that (now cancelled) element operation. Bits that are "1" will cancel their Write-Hazard and allow the Function Unit to proceed with that element's operation.
- The 6600 "Q-Table" that records, for each register, the last Function Unit (in instruction issue order) that is to write its result to that register, shall be augmented with "history" capability that aids and assists in "rollback" of "nameless" registers, should an exception or interrupt occur. "History" is simply a (short) queue (stack) that preserves, in instruction-issue order, a record of the previous Function Unit(s) that targetted each register as a destination.
- Function Units will have both src and destination Reservation Stations (latches) in order to buffer incoming and outgoing data. This to make best use of (limited) inter-Function-Unit bus bandwidth.
- Crossbar Routing from the Register File will be on the source registers only: Function Units will route directly to and be hard-wired associated with one of four register banks.
- Additional "Operand Forwarding" crossbar(s) will be added that bypass the register file entirely, to be used exclusively for registers that have specifically been identified as "nameless".
- Function Units will be the front-end to shared pipelined concurrent ALUs. The input src registers will come from the latches associated with the Function Unit, and will put the result back into the destination latch associated with that same Function Unit.
- Pairs of 32-bit Function Units will handle 64-bit operations, with the 32-bit src Reservation Stations (latches) "teaming up" to store 64-bit src register values, and likewise the 32-bit destination latches for the same (paired) Function Units.
- 32-bit Function Units will handle 8 and 16 bit operations in cases where batches of operations may be (easily, conveniently) allocated to a 32-bit-wide SIMD-style (predicated) ALU.
- Additional 8-bit Function Units (in groups of 4) will handle 8-bit operations as well as pair up to handle 16-bit operations in cases where neither 8 nor 16 bit operations can be (conveniently, easily) allocated to parallel (SIMD-like) ALUs. This to handle corner-cases and to not jam up the 32-bit Function Units with single-byte operations (resulting in only 25% utilisation).
- Allocation of an operation to a 32-bit ALU will block the corresponding 8/16-bit Function Unit(s) for that register, and vice-versa. 8/16-bit operations will however not block the remaining (unallocated) bytes of the same register from being utilised.
- Spectre timing attacks will be dealt with by ensuring that there are no side-channels between cores in the usual ways (no shared DIV unit, correct use of L1 cache), however there will be an addition of a "Speculation Fence" instruction (or hint) that will reset the internal state to a known quiescent state. This involves cancellation of all speculation, cancellation of "nameless" registers, committing outstanding register writes to the register file, and cancelling all Function Units waiting for read hazards. This to be automatically done on any exceptions or interrupts.
Register File
There shall be two 127-entry 64-bit register files: one for floating-point, the other for integer operations. Each shall have byte-level write-enable lines, and shall be divided into 4-way 2R1W banks that are split into odd-even register numbers and further split into hi-32 and lo-32 bits.
In this way, 2 simultaneous 64-bit operations may write to the register file (as long as the destinations have odd and even numbers), or 4 simultaneous 32-bit operations likewise. byte-level write-enable is so that writes may be performed down to the 16-bit and 8-bit level without requiring additional reads.
Additionally, if a read is requested for a register that is currently being written, the written value shall be "passed through" on the same cycle, such that the register file may effectively be used as an "Operand Forwarding" Channel.
Function Units
Commit Phase (instruction order preservation)
6600 Scoreboards
6600 Scoreboards are usually viewed as incomplete: incapable of register renaming and precise exceptions are two of the perceived flaws. These flaws do not exist, however it takes some explaining.
Q-Table (FU to Register Lookup)
The Q Table is a lookup table that records (in binary form in the original 6600, however unary bit-wise form - N Function Unit bits and M register bits - can be recommended) the last Function Unit that, in instruction issue order, is to write to any given register.
However, to support "nameless" registers, the Q-Table shall support multiple (historical) entries, recording the history of the previous Function Unit that was to write to each register. When historic entries exist (non-empty), the following shall occur:
- All Function Units with historic entries shall not commit their values to the register file, even if they are free to do so.
- All Function Units with historic entries shall hold a "write hazard" against their dependencies that are waiting for that "nameless" result.
- When a dependent Function Unit has cleared all possibility of an Exception being raised, it shall drop the write hazard on the "nameless" source.
- If a "nameless" Function Unit needs to generate an Exception, it does so in the standard way (see "Exceptions"), however, in doing so it will also result in a roll back of the Q-Table for all and any cancelled Function Units, to previous (historic) Q-Table values for the relevant destination registers. Once rolled back, the Function Unit must store its result in the register file, prior to permitting the Exception to proceed.
- Likewise If a dependent Function Unit has to generate an exception, and its source Function Units are "nameless", the "nameless" Function Units must also "roll back", store their results, and finally permit the Exception to trigger.
- Likewise, all other "nameless" results must also be "rolled back", except unlike the Function Units triggering the exception they may roll back to the newest "nameless" historical Q-Table entry (if they have not already been cancelled by the FU triggering the exception).
Bear in mind that exceptions (like all operations that are ready to commit) may only occur in-order (following a FU-to-FU "link" bit), and may only occur if the Function Unit is entirely free of write hazards.
FU-to-FU Dependency Matrix
The Function-Unit to Function-Unit Dependency Matrix expresses the read and write hazards - dependencies - between Function Units.
Branch Speculation
Branch speculation is done by preventing instructions from becoming "writeable" until the Branch Unit knows if it has resolved or not. This is done with the addition of "Shadow" lines, as shown below:
This image reproduced with kind permission, Copyright (C) Mitch Alsup
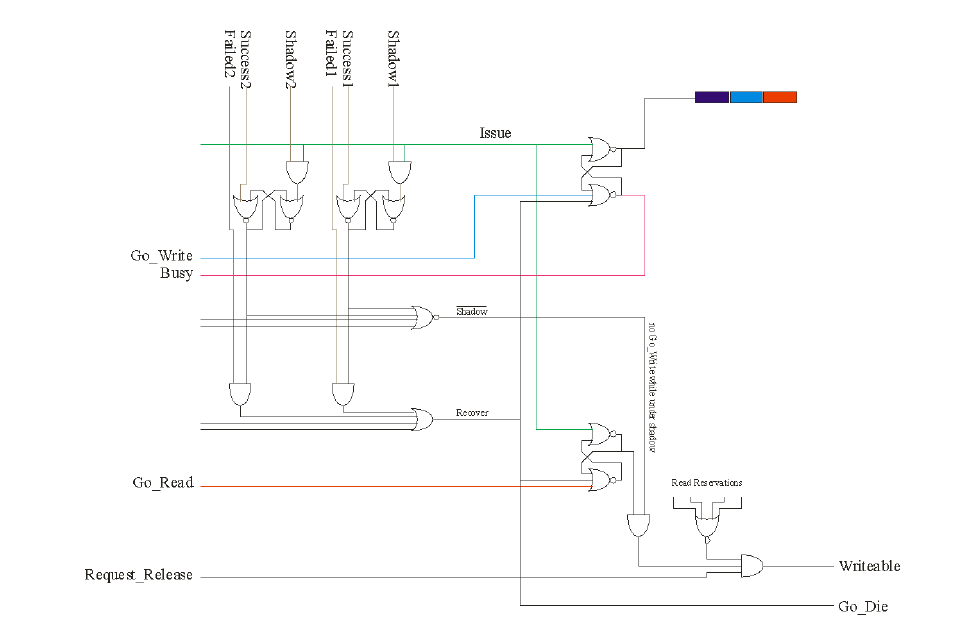
Note that there are multiple "Shadow" signals, coming not just from Branch Speculation but also from predication and exception shadows.
On a "Failed" signal, the instruction is told to "Go Die". This is passed to the Computation Unit as well. When all "Success" signals are raised the instruction is permitted to enter "Writeable".
Exceptions
Exceptions shall be handled by each instruction that may throw an exception having and holding a "Shadow" wire over all dependent Function Units, in exactly the same way as Branch Speculation. Likewise, dependent instructions are prevented and prohibited from entering the "Writeable" state.
Dependent downstream instructions, if the exception is thrown, shall have the "Failed" bit ASSERTED (by the Function Unit throwing the exception) such that the down-stream dependent instruction is told to "Go Die".
If the point is reached at which the instruction knows that the Exception cannot possibly occur, the "Success" signal is raised instead, thus cancelling the "hold" over dependent downstream instructions - again in exactly the same way as Branch Speculation "Success".
Exceptions may only be actually raised if they are at the front of the instruction queue, i.e. if they are free of write hazards. See section on "Function Unit Commit" phase, as the Function Units have a "link bit" that preserves the instruction issue order, which must also be respected.
Spectre-style timing mitigation
Spectre-style timing attacks are defined by one instruction issue affecting the completion time of past and future instructions. The key insight to mitigation against such attacks is to note that arbitrary untrusted instructions must not be permitted to affect trusted instructions. Consequently as long as there is a firebreak (a "Fence") between trusted and untrusted, timing attacks can be held off.
Two instructions ("hints") shall therefore be added:
- One that stops speculation, multi-issue and any out-of-order resource allocation for a minimum of 16 instructions.
- Another that cancels all speculation and reservations, cancels "nameless" registers, waits for and ensures that all outstanding instructions have completed and committed, before permitting the processor to continue further.
This latter shall occur unconditionally without requiring a special instruction to be called, on ECALL as well as all exceptions and interrupts.
ALU design
There is a separate pipelined alu for fdiv/fsqrt/frsqrt/idiv/irem that is possibly shared between 2 or 4 cores.
The main ALUs are each a unified ALU for i8-i64/f16-f64 where the ALU is split into lanes with separate instructions for each 32-bit half. So, the multiplier should be capable of 64-bit fmadd, 2x32-bit fmadd, 4x16-bit fmadd, 1x32-bit fmadd + 2x16-bit fmadd (in either order), and all (8/16/32/64) sizes of integer mul/mulhsu/mulh/mulhu in 2 groups of 32-bits. We can implement fmul using fmadd with 0 (make sure that we get the right sign bit for 0 for all rounding modes).