Revision History
- v0.00 05may2022 first created
- v0.01 06may2022 initial first draft
- v0.02 08may2022 add scenarios / use-cases
- v0.03 09may2022 add draft image for scenario
- v0.04 14may2022 add appendix with other research
- v0.05 14jun2022 update images (thanks to Veera)
Table of Contents
Why in the 2020s would you invent a new Vector ISA
(The short answer: you don't. Extend existing technology: on the shoulders of giants)
Inventing a new Scalar ISA from scratch is over a decade-long task including simulators and compilers: OpenRISC 1200 took 12 years to mature. Stable Open ISAs require Standards and Compliance Suites that take more. A Vector or Packed SIMD ISA to reach stable general-purpose auto-vectorization compiler support has never been achieved in the history of computing, not with the combined resources of ARM, Intel, AMD, MIPS, Sun Microsystems, SGI, Cray, and many more. (Hand-crafted assembler and direct use of intrinsics is the Industry-standard norm to achieve high-performance optimisation where it matters). GPUs fill this void both in hardware and software terms by having ultra-specialist compilers (CUDA) that are designed from the ground up to support Vector/SIMD parallelism, and associated standards (SPIR-V, Vulkan, OpenCL) managed by the Khronos Group, with multi-man-century development committment from multiple billion-dollar-revenue companies, to sustain them.
Therefore it begs the question, why on earth would anyone consider this task, and what, in Computer Science, actually needs solving?
First hints are that whilst memory bitcells have not increased in speed since the 90s (around 150 mhz), increasing the bank width, striping, and datapath widths and speeds to the same has, with significant relative latency penalties, allowed apparent speed increases: 3200 mhz DDR4 and even faster DDR5, and other advanced Memory interfaces such as HBM, Gen-Z, and OpenCAPI's OMI, all make an effort (all simply increasing the parallel deployment of the underlying 150 mhz bitcells), but these efforts are dwarfed by the two nearly three orders of magnitude increase in CPU horsepower over the same timeframe. Seymour Cray, from his amazing in-depth knowledge, predicted that the mismatch would become a serious limitation, over two decades ago.
The latency gap between that bitcell speed and the CPU speed can do nothing to help Random Access (unpredictable reads/writes). Cacheing helps only so much, but not with some types of workloads (FFTs are one of the worst) even though they are fully deterministic. Some systems at the time of writing are now approaching a Gigabyte of L4 Cache, by way of compensation, and as we know from experience even that will be considered inadequate in future.
Efforts to solve this problem by moving the processing closer to or directly integrated into the memory have traditionally not gone well: Aspex Microelectronics, Elixent, these are parallel processing companies that very few have heard of, because their software stack was so specialist that it required heavy investment by customers to utilise. D-Matrix, a Systolic Array Processor, is a modern incarnation of the exact same "specialist parallel processing" mistake, betting heavily on AI with Matrix and Convolution Engines that can do no other task. Aspex only survived by being bought by Ericsson, where its specialised suitability for massive wide Baseband FFTs saved it from going under. The huge risk is that any "better AI mousetrap" created by an innovative competitor that comes along quickly renders a too-specialist design obsolete.
NVIDIA and other GPUs have taken a different approach again: massive parallelism with more Turing-complete ISAs in each, and dedicated slower parallel memory paths (GDDR5) suited to the specific tasks of 3D, Parallel Compute and AI. The complexity of this approach is only dwarfed by the amount of money poured into the software ecosystem in order to make it accessible, and even then, GPU Programmers are a specialist and rare (expensive) breed.
Second hints as to the answer emerge from an article "SIMD considered harmful" which illustrates a catastrophic rabbit-hole taken by Industry Giants ARM, Intel, AMD, since the 90s (over 3 decades) whereby SIMD, an Order(N6) opcode proliferation nightmare, with its mantra "make it easy for hardware engineers, let software sort out the mess" literally overwhelming programmers with thousands of instructions. Specialists charging clients for assembly-code Optimisation Services are finding that AVX-512, to take an example, is anything but optimal: overall performance of AVX-512 actually decreases even as power consumption goes up.
Cray-style Vectors solved, over thirty years ago, the opcode proliferation
nightmare. Only the NEC SX Aurora however truly kept the Cray Vector
flame alive, until RISC-V RVV and now SVP64 and recently MRISC32 joined
it. ARM's SVE/SVE2 is critically flawed (lacking the Cray setvl
instruction that makes a truly ubiquitous Vector ISA) in ways that
will become apparent over time as adoption increases. In the meantime
programmers are, in direct violation of ARM's advice on how to use SVE2,
trying desperately to understand it by applying their experience
of Packed SIMD NEON. The advice from ARM
not to create SVE2 assembler that is hardcoded to fixed widths is being
disregarded, in favour of writing multiple identical implementations
of a function, each with a different hardware width, and compelling
software to choose one at runtime after probing the hardware.
Even RISC-V, for all that we can be grateful to the RISC-V Founders for reviving Cray Vectors, has severe performance and implementation limitations that are only really apparent to exceptionally experienced assembly-level developers with a wide, diverse depth in multiple ISAs: one of the best and clearest is a ycombinator post by adrian_b.
Adrian logically and concisely points out that the fundamental design assumptions and simplifications that went into the RISC-V ISA have an irrevocably damaging effect on its viability for high performance use. That is not to say that its use in low-performance embedded scenarios is not ideal: in private custom secretive commercial usage it is perfect. Trinamic, an early adopter, created their TMC2660 Stepper IC replacing ARM with RISC-V and saving themselves USD 1 in licensing royalties per product are a classic case study. Ubiquitous and common everyday usage in scenarios currently occupied by ARM, Intel, AMD and IBM? not so much. Even though RISC-V has Cray-style Vectors, the whole ISA is, unfortunately, fundamentally flawed as far as power efficient high performance is concerned.
Slowly, at this point, a realisation should be sinking in that, actually, there aren't as many really truly viable Vector ISAs out there, as the ones that are evolving in the general direction of Vectorization are, in various completely different ways, flawed.
Successfully identifying a limitation marks the beginning of an opportunity
We are nowhere near done, however, because a Vector ISA is a superset of a Scalar ISA, and even a Scalar ISA takes over a decade to develop compiler support, and even longer to get the software ecosystem up and running.
Which ISAs, therefore, have or have had, at one point in time, a decent Software Ecosystem? Debian supports most of these including s390:
- SPARC, created by Sun Microsystems and all but abandoned by Oracle. Gaisler Research maintains the LEON Open Source Cores but with Oracle's reputation nobody wants to go near SPARC.
- MIPS, created by SGI and only really commonly used in Network switches. Exceptions: Ingenic with embedded CPUs, and China ICT with the Loongson supercomputers.
- x86, the most well-known ISA and also one of the most heavily litigously-protected.
- ARM, well known in embedded and smartphone scenarios, very slowly making its way into data centres.
- OpenRISC, an entirely Open ISA suitable for embedded systems.
- s390, a Mainframe ISA very similar to Power.
- Power ISA, a Supercomputing-class ISA, as demonstrated by two out of three of the top500.org supercomputers using around 2 million IBM POWER9 Cores each.
- ARC, a competitor at the time to ARM, best known for use in Broadcom VideoCore IV.
- RISC-V, with a software ecosystem heavily in development and with rapid expansion in an uncontrolled fashion, is set on an unstoppable and inevitable trainwreck path to replicate the opcode conflict nightmare that plagued the Power ISA, two decades ago.
- Tensilica, Andes STAR and Western Digital for successful commercial proprietary ISAs: Tensilica in Baseband Modems, Andes in Audio DSPs, WD in HDDs and SSDs. These are all astoundingly commercially successful multi-billion-unit mass volume markets that almost nobody knows anything about, outside their specialised proprietary niche. Included for completeness.
In order of least controlled to most controlled, the viable candidates for further advancement are:
- OpenRISC 1200, not controlled or restricted by anyone. no patent protection.
- RISC-V, touted as "Open" but actually strictly controlled under Trademark License: too new to have adequate patent pool protection, as evidenced by multiple adopters having been hit by patent lawsuits. (Agreements between RISC-V Members to not engage in patent litigation does nothing to stop third party patents that legitimately pre-date the newly-created RISC-V ISA)
- MIPS, SPARC, ARC, and others, simply have no viable publicly managed ecosystem. They work well within their niche markets.
- Power ISA: protected by IBM's extensive patent portfolio for Members of the OpenPOWER Foundation, covered by Trademarks, permitting and encouraging contributions, and having software support for over 20 years.
- ARM, not permitting Open Licensing, they survived in the early 90s only by doing a deal with Samsung for an in-perpetuity Royalty-free License, in exchange for GBP 3 million and legal protection through Samsung Research. Several large Corporations (Apple most notably) have licensed the ISA but not ARM designs: the barrier to entry is high and the ISA itself protected from interference as a result.
- x86, famous for an unprecedented Court Ruling in 2004 where a Judge "banged heads together" and ordered AMD and Intel to stop wasting his time, make peace, and cross-license each other's patents, anyone wishing to use the x86 ISA need only look at Transmeta, SiS, the Vortex x86, and VIA EDEN processors, and see how they fared.
- s390, IBM's mainframe ISA. Nowhere near as well-known as x86 lawsuits, but the 800lb "Corporate Gorilla Syndrome" seems not to have deterred one particularly disingenuous group from performing illegal Reverse-Engineering.
By asking the question, "which ISA would be the best and most stable to base a Vector Supercomputing-class Extension on?" where patent protection, software ecosystem, open-ness and pedigree all combine to reduce risk and increase the chances of success, there is really only one candidate.
Of all of these, the only one with the most going for it is the Power ISA.
The summary of advantages, then, of the Power ISA is that:
- It has a 25-year software ecosystem, with RHEL, Fedora, Debian and more.
- Amongst many other features it has Condition Registers which can be used by Branches, greatly reducing pressure on the main register files.
- IBM's extensive 20+ years of patents is available, royalty-free, to protect implementors as long as they are also members of the OpenPOWER Foundation
- IBM designed and maintained the Power ISA as a Supercomputing class ISA from its inception over 25 years ago.
- Coherent distributed memory access is possible through OpenCAPI
- Extensions to the Power ISA may be submitted through an External RFC Process that does not require membership of OPF.
From this strong base, the next step is: how to leverage this foundation to take a leap forward in performance and performance/watt, without losing all the advantages of an ubiquitous software ecosystem, the lack of which has historically plagued other systems and relegated them to a risky niche market?
How do you turn a Scalar ISA into a Vector one?
The most obvious question before that is: why on earth would you want to?
As explained in the "SIMD Considered Harmful" article, Cray-style
Vector ISAs break the link between data element batches and the
underlying architectural back-end parallel processing capability.
Packed SIMD explicitly smashes that width right in the face of the
programmer and expects them to like it. As the article immediately
demonstrates, an arbitrary-sized data set has to contend with
an insane power-of-two Packed SIMD cascade at both setup and teardown
that routinely adds literally an order
of magnitude increase in the number of hand-written lines of assembler
compared to a well-designed Cray-style Vector ISA with a setvl
instruction.
Packed SIMD looped algorithms actually have to
contain multiple implementations processing fragments of data at
different SIMD widths: Cray-style Vectors have just the one, covering not
just current architectural implementations but future ones with
wider back-end ALUs as well.
Assuming then that variable-length Vectors are obviously desirable, it becomes a matter of how, not if. Both Cray and NEC SX Aurora went the way of adding explicit Vector opcodes, a style which RVV copied and modernised. In the case of RVV this introduced 192 new instructions on top of an existing 95+ for base RV64GC. Adding 200% more instructions than the base ISA seems unwise: at least, it feels like there should be a better way, particularly on close inspection of RVV as an example, the basic arithmetic operations are massively duplicated: scalar-scalar from the base is joined by both scalar-vector and vector-vector and predicate mask management, and transfer instructions between all the same, which goes a long way towards explaining why there are twice as many Vector instructions in RISC-V as there are in the RV64GC Scalar base.
The question then becomes: with all the duplication of arithmetic operations just to make the registers scalar or vector, why not leverage the existing Scalar ISA with some sort of "context" or prefix that augments its behaviour? Separate out the "looping" from "thing being looped on" (the elements), make "Scalar instruction" synonymous with "Vector Element instruction" and through nothing more than contextual augmentation the Scalar ISA becomes the Vector ISA. Then, by not having to have any Vector instructions at all, the Instruction Decode phase is greatly simplified, reducing design complexity and leaving plenty of headroom for further expansion.

Remarkably this is not a new idea. Intel's x86 REP instruction
gives the base concept, and the Z80 had something similar.
But in 1994 it was Peter Hsu, the designer
of the MIPS R8000, who first came up with the idea of Vector-augmented
prefixing of an existing Scalar ISA. Relying on a multi-issue Out-of-Order Execution Engine,
the prefix would mark which of the registers were to be treated as
Scalar and which as Vector, then, treating the Scalar "suffix" instruction
as a guide and making "scalar instruction" synonymous with "Vector element",
perform a REP-like loop that
jammed multiple scalar operations into the Multi-Issue Execution
Engine. The only reason that the team did not take this forward
into a commercial product
was because they could not work out how to cleanly do OoO
multi-issue at the time (leveraging Multi-Issue is the most logical
way to exploit the Vector-Prefix concept)
In its simplest form, then, this "prefixing" idea is a matter of:
- Defining the format of the prefix
- Adding a
setvlinstruction - Adding Vector-context SPRs and working out how to do context-switches with them
- Writing an awful lot of Specification Documentation (4 years and counting)
Once the basics of this concept have sunk in, early advancements quickly follow naturally from analysis of the problem-space:
- Expanding the size of GPR, FPR and CR register files to provide 128 entries in each. This is a bare minimum for GPUs in order to keep processing workloads as close to a LOAD-COMPUTE-STORE batching as possible.
- Predication (an absolutely critical component for a Vector ISA),
then the next logical advancement is to allow separate predication masks
to be applied to both the source and the destination, independently.
(Readers familiar with Vector ISAs will recognise this as a back-to-back
VGATHER-VSCATTER) - Element-width overrides: most Scalar ISAs today are 64-bit only, with primarily Load and Store being able to handle 8/16/32/64 and sometimes 128-bit (quad-word), where Vector ISAs need to go as low as 8-bit arithmetic, even 8-bit Floating-Point for high-performance AI. Rather than waste opcode space adding all such operations at different bitwidths, let the prefix redefine (override) the element width, without actually altering the Scalar ISA at all.
- "Reordering" of the assumption of linear sequential element access, for Matrices, rotations, transposition, Convolutions, DCT, FFT, Parallel Prefix-Sum and other common transformations that require significant programming effort in other ISAs.
All of these things come entirely from "Augmentation" of the Scalar operation being prefixed: at no time is the Scalar operation's binary pattern decoded differently compared to when it is used as a Scalar operation. From there, several more "Modes" can be added, including
- saturation, which is needed for Audio and Video applications
- "Reverse Gear" which runs the Element Loop in reverse order (needed for Prefix Sum)
- Data-dependent Fail-First, which emerged from asking the simple question, "If modern Vector ISAs have Load/Store Fail-First, and the Power ISA has Condition Codes, why not make Conditional early-exit from Arithmetic operation looping?"
- over 500 Branch-Conditional Modes emerge from application of Boolean Logic in a Vector context, on top of an already-powerful Scalar Branch-Conditional/Counter instruction
All of these festures are added as "Augmentations", to create of the order of 1.5 million instructions, none of which decode the 32-bit scalar suffix any differently.
What is missing from Power Scalar ISA that a Vector ISA needs?
Remarkably, very little: the devil is in the details though.
- The traditional
iotainstruction may be synthesised with an overlapping add, that stacks up incrementally and sequentially. Although it requires two instructions (one to start the sum-chain) the technique has the advantage of allowing increments by arbitrary amounts, and is not limited to addition, either. - Big-integer addition (arbitrary-precision arithmetic) is an
emergent characteristic from the carry-in, carry-out capability of
Power ISA
addeinstruction.sv.addeas a BigNum add naturally emerges from the sequential carry-flag chaining of these scalar instructions. - The Condition Register Fields of the Power ISA make a great candidate
for use as Predicate Masks, particularly when combined with
Vectorized
cmpand Vectorizedcrand,crxoretc.
It is only when looking slightly deeper into the Power ISA that certain things turn out to be missing, and this is down in part to IBM's primary focus on the 750 Packed SIMD opcodes at the expense of the 250 or so Scalar ones. Examples include that transfer operations between the Integer and Floating-point Scalar register files were dropped approximately a decade ago after the Packed SIMD variants were considered to be duplicates. With it being completely inappropriate to attempt to Vectorize a Packed SIMD ISA designed 20 years ago with no Predication of any kind, the Scalar ISA, a much better all-round candidate for Vectorization (the Scalar parts of Power ISA) is left anaemic.
A particular key instruction that is missing is MV.X which is
illustrated as GPR(dest) = GPR(GPR(src)). This horrendously
expensive instruction causing a huge swathe of Register Hazards
in one single hit is almost never added to a Scalar ISA but
is almost always added to a Vector one. When MV.X is
Vectorized it allows for arbitrary
remapping of elements within a Vector to positions specified
by another Vector. A typical Scalar ISA will use Memory to
achieve this task, but with Vector ISAs the Vector Register Files are
usually so enormous, and so far away from Memory, that it is easier and
more efficient, architecturally, to provide these Indexing instructions.
Fortunately, with the ISA Working Group being willing to consider RFCs (Requests For Change) these omissions have the potential to be corrected.
One deliberate decision in SVP64 involves Predication. Typical Vector ISAs have quite comprehensive arithmetic and logical operations on Predicate Masks, and it turns out, unsurprisingly, that the Scalar Integer side of Power ISA already has most of them. If CR Fields were the only predicates in SVP64 it would put pressure on to start adding the exact same arithmetic and logical operations that already exist in the Integer opcodes, which is less than desirable. Instead of taking that route the decision was made to allow both Integer and CR Fields to be Predicate Masks, and to create Draft instructions that provide better transfer capability between CR Fields and Integer Register files.
Beyond that, further extensions to the Power ISA become much more
domain-specific, such as adding bitmanipulation for Audio, Video
and Cryptographic use-cases, or adding Transcendentals (LOG1P,
ATAN2 etc) for 3D and other GPU workloads. The huge advantage here
of the SVP64 "Prefix" approach is that anything added to the Scalar ISA
automatically is inherently added to the Vector one as well, and
because these GPU and Video opcodes have been added to the CPU ISA,
Software Driver development and debugging is dramatically simplified.
Which brings us to the next important question: how is any of these CPU-centric Vector-centric improvements relevant to power efficiency and making more effective use of resources?
Simpler more compact programs saves power
The first and most obvious saving is that, just as with any Vector ISA, the amount of data processing requested and controlled by each instruction is enormous, and leaves the Decode and Issue Engines idle, as well as the L1 I-Cache. With programs being smaller, chances are higher that they fit into L1 Cache, or that the L1 Cache may be made smaller: either way is a considerable O(N2) power-saving.
Even a Packed SIMD ISA could take limited advantage of a higher bang-per-buck for limited specific workloads, as long as the stripmining setup and teardown is not required. However a 2-wide Packed SIMD instruction is nowhere near as high a bang-per-buck ratio as a 64-wide Vector Length.
Realistically, for general use cases however it is extremely common
to have the Packed SIMD setup and teardown. strncpy for VSX is an
astounding 240 hand-coded assembler instructions where it is around
12 to 14 for both RVV and SVP64. Worst case (full algorithm unrolling
for Massive FFTs) the L1 I-Cache becomes completely ineffective, and in
the case of the IBM POWER9 with a little-known design flaw not
normally otherwise encountered this results in
contention between the L1 D and I Caches at the L2 Bus, slowing down
execution even further. Power ISA 3.1 MMA (Matrix-Multiply-Assist)
requires loop-unrolling to contend with non-power-of-two Matrix
sizes: SVP64 does not (as hinted at below).
Figures 8 and 9
illustrate the process of concatenating copies of data in order
to match RADIX2 limitations of MMA.
Additional savings come in the form of SVREMAP. Like the
hardware-assist of Google's TPU mentioned on p9 of the above MMA paper,
SVREMAP is a hardware
index transformation system where the normally sequentially-linear
Vector element access may be "Re-Mapped" to limited but algorithmic-tailored
commonly-used deterministic schedules, for example Matrix Multiply,
DCT, or FFT. A full in-register-file 5x7 Matrix Multiply or a 3x4 or
2x6 with optional in-place transpose, mirroring or rotation
on any source or destination Matrix
may be performed in as little as 4 instructions, one of which
is to zero-initialise the accumulator Vector used to store the result.
If addition to another Matrix is also required then it is only three
instructions.
Not only that, but because the "Schedule" is an abstract concept separated from the mathematical operation, there is no reason why Matrix Multiplication Schedules may not be applied to Integer Mul-and-Accumulate, Galois Field Mul-and-Accumulate, Logical AND-and-OR, or any other future instruction such as Complex-Number Multiply-and-Accumulate or Abs-Diff-and-Accumulate that a future version of the Power ISA might support. The flexibility is not only enormous, but the compactness unprecedented. RADIX2 in-place DCT may be created in around 11 instructions using the Triple-loop DCT Schedule. The only other processors well-known to have this type of compact capability are both VLIW DSPs: TI's TMS320 Series and Qualcom's Hexagon, and both are targetted at FFTs only.
There is no reason at all why future algorithmic schedules should not be proposed as extensions to SVP64 (sorting algorithms, compression algorithms, Sparse Data Sets, Graph Node walking for example). (Bear in mind that the submission process will be entirely at the discretion of the OpenPOWER Foundation ISA WG, something that is both encouraged and welcomed by the OPF.)
One of SVP64's current limitations is that it was initially designed for 3D and Video workloads as a hybrid GPU-VPU-CPU. This resulted in a heavy focus on adding hardware-for-loops onto the Registers. After more than three years of development the realisation hit that the SVP64 concept could be expanded to Coherent Distributed Memory. This astoundingly powerful concept is explored in the next section.
Coherent Deterministic Hybrid Distributed In-Memory Processing
It is not often that a heading in an article can legitimately contain quite so many comically-chained buzzwords, but in this section they are justified. As hinted at in the first section, the last time that memory was the same speed as processors was the Pentium III and Motorola 88100 era: 133 and 166 mhz SDRAM was available, and CPUs were about the same rate. DRAM bitcells simply cannot exceed these rates, yet the pressure from Software Engineers is to make sequential algorithm processing faster and faster because parallelising of algorithms is simply too difficult to master, and always has been. Thus whilst DRAM has to go parallel (like RAID Striping) to keep up, CPUs are now at 8-way Multi-Issue 5 ghz clock rates and are at an astonishing four levels of cache (L1 to L4).
It should therefore come as no surprise that attempts are being made
to move (distribute) processing closer to the DRAM Memory, firmly
on the opposite side of the main CPU's L1/2/3/4 Caches,
where a simple LOAD-COMPUTE-STORE-LOOP workload easily illustrates
why this approach is compelling. However
the alarm bells ring here at the keyword "distributed", because by
moving the processing down next to the Memory, even onto
the same die as the DRAM, the speed of any
of the parallel Processing Elements (PEs) would likely drop
by almost two orders of magnitude (5 ghz down to 150 mhz),
the simplicity of each PE has, for pure pragmatic reasons,
to drop by several
orders of magnitude as well.
Things that the average "sequential algorithm"
programmer
takes for granted such as SMP, Cache Coherency, Virtual Memory,
spinlocks (atomic locking, mutexes), all of these are either outright gone
or expected that the programmer shall explicitly contend with
(even if that programmer is the Compiler Developer). There's definitely
not going to be a standard OS: the PEs will be too basic, too
resource-constrained, and definitely too busy.
To give an extreme example: Aspex's Array-String Processor, which was 4096 2-bit SIMD PEs each with 256 bytes of Content Addressable Memory, was capable of literally a hundred-fold improvement in performance over Scalar CPUs such as the Pentium III of its era, all on a 3 watt budget at only 250 mhz in 130 nm. Yet to take proper advantage of its capability required an astounding 5-10 days per line of assembly code because multiple versions of an algorithm had to be hand-crafted then compared, and only the best one selected: all others discarded. 20 lines of optimised Assembler taking three to six months to write can in no way be termed "productive", yet this extreme level of unproductivity is an inherent side-effect of going down the parallel-processing rabbithole where the cost of providing "Traditional" programmabilility (Virtual Memory, SMP) is worse than counter-productive, it's often outright impossible.
Similar to how GPUs achieve astounding task-dedicated
performance by giving
ALUs 30% of total silicon area and sacrificing the ability to run
General-Purpose programs, Aspex, Google's Tensor Processor and D-Matrix
likewise took this route and made the same compromise.
In short, we are in "Programmer's nightmare" territory
Having dug a proverbial hole that rivals the Grand Canyon, and jumped in it feet-first, the next task is to piece together a strategy to climb back out and show how falling back in can be avoided. This takes some explaining, and first requires some background on various research efforts and commercial designs. Once the context is clear, their synthesis can be proposed. These are:
ZOLC: Zero-Overhead Loop Control
Zero-Overhead Looping is the concept of automatically running a set sequence
of instructions a predetermined number of times, without requiring
a branch. This is conceptually similar but
slightly different from using Power ISA bc in CTR
(Counter) Mode to create loops, because in ZOLC the branch-back is automatic.
The simplest longest commercially successful deployment of Zero-overhead looping has been in Texas Instruments TMS320 DSPs. Up to fourteen sub-instructions within the VLIW word may be repeatedly deployed on successive clock cycles until a countdown reaches zero. This extraordinarily simple concept needs no branches, and has no complex Register Hazard Management in the hardware because it is down to the programmer (or, the compiler), to ensure data overlaps do not occur. Careful crafting of those 14 instructions can keep the ALUs 100% occupied for sustained periods, and the iconic example for which the TI DSPs are renowned is that an entire inner loop for large FFTs can be done with that one VLIW word: no stalls, no stopping, no fuss, an entire 1024 or 4096 wide FFT Layer in one instruction.
The key aspect of these very simplistic countdown loops as far as we are concerned: is: *they are deterministic*.
Zero-Overhead Loop Control takes this basic "single loop" concept way further: both nested loops and conditional exit are included, but also arbitrary control-jumping from the current inner loop out to an entirely different loop, all based on conditions determined dynamically at runtime.
Even when deployed on as basic a CPU as a single-issue in-order RISC core, the performance and power-savings were astonishing: between 27 and 75% reduction in algorithm completion times were achieved compared to a more traditional branch-speculative in-order RISC CPU. MPEG Encode's timing, the target algorithm specifically picked by the researcher due to its high complexity with 6-deep nested loops and conditional execution that frequently jumped in and out of at least 2 loops, came out with an astonishing 43% improvement in completion time. 43% less instructions executed is an almost unheard-of level of optimisation: most ISA designers are elated if they can achieve 5 to 10%. The reduction was so compelling that ST Microelectronics put it into commercial production in one of their embedded CPUs, the ST120 DSP-MCU.
The kicker: when implementing SVP64's Matrix REMAP Schedule, the VLSI design of its triple-nested for-loop system turned out to be remarkably similar to the core nested for-loop engine of ZOLC. In hindsight this should not have come as a surprise, because both are basically nested for-loops that do not need branches to issue instructions.
The important insight is, however, that if ZOLC can be general-purpose and apply deterministic nested looped instruction schedules to more than just registers (unlike SVP64 in its current incarnation) then so can SVP64.
OpenCAPI and Extra-V
OpenCAPI is a deterministic high-performance, high-bandwidth, low-latency cache-coherent Memory-access Protocol that is integrated into IBM's Supercomputing-class POWER9 and POWER10 processors.
(Side note: POWER10 *only* has OpenCAPI Memory interfaces: an astounding number of them, with overall bandwidth so high it's actually difficult to conceptualise. An OMI-to-DDR4/5 Bridge PHY is therefore required to connect to standard Memory DIMMs.)
Extra-V appears to be a remarkable research project based on OpenCAPI that, by assuming that the map of edges (excluding the actual data) in any given arbitrary data graph could be kept by the main CPU in-memory, could distribute and delegate a limited-capability deterministic but most importantly data-dependent node-walking schedule actually right down into the memory itself (on the other side of that L1-4 cache barrier). A miniature processor (non-Turing-complete) analysed the data it had read (at the Memory), and determined if it should notify the main processor that this "Node" is worth investigating, or if the Graph node-walk should split in a different direction. Thanks to the OpenCAPI Standard, which takes care of Virtual Memory abstraction, locking, and cache-coherency, many of the nightmare problems of other more explicit parallel processing paradigms disappear.
The similarity to ZOLC should not have gone unnoticed: where ZOLC has nested conditional for-loops Extra-V appears to have just the one conditional for-loop, but the key strategically-crucial part of this multi-faceted puzzle is that due to the deterministic and coherent nature of Extra-V, the processing of the loops, which requires a tiny non-Turing-Complete processor, is not done close to or by the main CPU at all: it is embedded right next to the memory.
The similarity to the D-Matrix Systolic Array Processing, Aspex Microelectronics Array-String Processing, and Elixent 2D Array Processing, should also not have gone unnoticed. All of these solutions utilised or utilise a more comprehensive Turing-complete von-Neumann "Management Core" to coordinate data passed in and out of PEs: none of them have or had something as powerful as OpenCAPI as part of that picture.
The fact that Neural Networks may be expressed as arbitrary Graphs, and comprise Sparse Matrices, should also have been noted by the reader interested in AI.
Snitch
Snitch is an elegant Memory-Coherent Barrel-Processor where registers
become "tagged" with a Memory-access Mode that went out of fashion
over forty years ago: Load-then-Auto-Increment. Expressed in c as
src = *x++, and requiring special Address Registers (PDP-11, 68000),
thanks to the RISC paradigm having gone too far,
the efficiency and effectiveness
of these Load-Store-with-Increment instructions has been
forgotten until Snitch.
What the designers did however was not to add any new Load-Store or Arithmetic instructions to the underlying RISC-V at all, but instead to "mark" registers with a tag which augmented (altered) the behaviour of existing instructions. These tags tell the CPU: when you are asked to carry out an add instruction on r6 and r7, do not take r6 or r7 from the register file, instead please perform a Cache-coherent Load-with-Increment on each, using special (hidden, implicit) Address Registers for each. Each new use of r6 therefore brings in an entirely new value directly from memory. Likewise on the second operand, r7, and likewise on the destination result which can be an automatic Coherent Store-and-increment directly into Memory.
*The act of "reading" or "writing" a register has been decoupled and intercepted, then connected transparently to a completely separate Coherent Memory Subsystem*
On top of a barrel-architecture the slowness of Memory access was not a problem because the Deterministic nature of classic Load-Store-Increment can be compensated for by having 8 Memory accesses scheduled underway and interleaved in a time-sliced fashion with an FPU that is correspondingly 8 times faster than the Coherent Memory accesses.
This design is reminiscent of the early Vector Processors of the late 1950s and early 1960s, which also critically relied on implicit auto-increment addressing. The CDC STAR-100 for example was specifically designed as a Memory-to-Memory Vector Processor. The barrel-architecture of Snitch neatly solves one of the inherent problems of those early designs (a mismatch with memory speed) and the presence of a full register file (non-tagged, normal, standard scalar registers) caters for a second limitation of pure Memory-based Vector Processors: temporary variables needed in the computation of intermediate results, which also had to go through memory, put an awfully high artificial load on Memory bandwidth.
The similarity to SVP64 should be clear: SVP64 Prefixing and the associated REMAP system is just another form of register "tagging" that augments what was formerly designated by its original authors as "just a Scalar ISA", tagging allows for dramatic implicit alteration with advanced behaviour not previously envisaged.
What Snitch brings to the table therefore is a further illustration of the concept introduced by Extra-V: where Extra-V brought information about Sparse-Distributed Data to the attention of the main CPU in a coherent fashion without the CPU having to ask for it, Snitch demonstrates a classic LOAD-COMPUTE-STORE cycle in the same distributed coherent manner, and does so with dramatically-reduced power consumption.
Bringing it all together
At this point we are well into a future revision of SVP64, one that clearly has some startlingly powerful potential: Supercomputing-class Multi-Issue Vector Engines kept 100% occupied in a 100% long-term sustained fashion with reduced complexity, reduced power consumption and reduced completion time, thanks to Deterministic Coherent Scheduling of the data fed in and out, or even moved down next to Memory.
This last part is where it normally gets hair-raising, but as ZOLC shows there is no reason at all why even complex algorithms such as MPEG cannot be run in a partially-deterministic manner, and anything that is deterministic can be Scheduled, coherently. Combine that with OpenCAPI which solves the many issues associated with SMP Virtual Memory and so on yet still allows Cache-Coherent Distributed Memory Access, and what was previously an intractable Computer Science problem for decades begins to look like there is a potential solution.
The Deterministic Schedules created by ZOLC should even be possible to identify their suitability for full off-CPU distributed processing, as long as OpenCAPI is integrated into the mix. What a compiler - or even the hardware - will be looking out for is a Basic Block of instructions that:
- begins with a LOAD (to be handled by OpenCAPI)
- contains some instructions that a given PE is capable of executing
- ends with a STORE (again: OpenCAPI)
For best results that would be wrapped with a Zero-Overhead Loop (which is offloaded - in full - down to the PE), where the Compiler (or hardware at runtime) could easily identify, in advance, the full range of Memory Addresses that the Loop is to encounter. Copies of loop-invariant data would need to be passed down to the remote PE: again, for simple-enough Basic Blocks, with assistance from the Compiler, loop-invariant inputs are easily identified. Parallel Processing opportunities should also be easy enough to create, simply by farming out different parts of a given Deterministic Zero-Overhead Loop to different PEs based on their proximity, bandwidth or ease of access to given Memory.
The importance of OpenCAPI in this mix cannot be underestimated, because it will be the means by which the main CPU coordinates its activities with the remote PEs, ensuring that LOAD/STORE Memory Hazards are not violated. It should also be straightforward to ensure that the offloading is entirely transparent to the developer, in fact this is a hard requirement because at any given moment there is the possibility that the PEs may be busy and it is the main CPU that has to complete the Processing Task itself.
It is also important to note that we are not necessarily talking about the Remote PEs executing the Power ISA, but if they do so it becomes much easier for the main CPU to take over in the event that PEs are currently occupied. Plus, the twin lessons that inventing ISAs, even a small one, is hard (mostly in compiler writing) and how complex GPU Task Scheduling is, are being heard loud and clear.
Put another way: if the PEs run a foriegn ISA, then the Basic Blocks embedded inside the ZOLC Loops must be in that ISA and therefore:
- In order that the main CPU can execute the same sequence if necessary, the CPU must support dual ISAs: Power and PE OR
- There must be a JIT binary-translator which either turns PE code into Power ISA code or vice-versa OR
- The compiler dual-compiles the original source code, and embeds both a Power binary and a PE binary into the ZOLC Basic Block OR
- All binaries are stored in an Intermediate Representation (LLVM-IR, SPIR-V) and JIT-compiled on-demand.
All of these would work, but it is simpler and a lot less work just to have the PEs execute the exact same ISA (or a subset of it). If however the concept of Hybrid PE-Memory Processing were to become a JEDEC Standard, which would increase adoption and reduce cost, a bit more thought is required here because ARM or Intel or MIPS might not necessarily be happy that a Processing Element (PE) has to execute Power ISA binaries. At least the Power ISA is much richer, more powerful, still RISC, and is an Open Standard, as discussed in a earlier sections.
A reasonable compromise as a JEDEC Standard is illustrated with the following diagram: a 3-way Bridge PHY that allows for full direct interaction between DRAM ICs, PEs, and one or more main CPUs ( a variant of the Northbridge and/or IBM POWER10 OMI-to-DDR5 PHY concept). It is also the ideal location for a "Management Core". If the 3-way Bridge (4-way if connectivity to other Bridge PHYs is also included) does not itself have PEs built-in then the ISA utilised on any PE or CPU is non-critical. The only concern regarding mixed ISAs is that the PHY should be capable of transferring all and any types of "Management" packets, particularly PE Virtual Memory Management and Register File Control (Context-switch Management given that the PEs are expected to be ALU-heavy and not capable of running a full SMP Operating System).
There is also no reason why this type of arrangement should not be deployed in Multi-Chip-Module (aka "Chiplet") form, giving all the advantages of the performance boost that goes with smaller line-drivers.

Transparently-Distributed Vector Processing
It is very strange to the author to be describing what amounts to a "Holy Grail" solution to a decades-long intractable problem that mitigates the anticipated end of Moore's Law: how to make it easy for well-defined workloads, expressed as a perfectly normal sequential program, compiled to a standard well-known ISA, to have the potential of being offloaded transparently to Parallel Compute Engines, all without the Software Developer being excessively burdened with a Parallel-Processing Paradigm that is alien to all their experience and training, as well as Industry-wide common knowledge.
Will it be that easy? ZOLC is, honestly, in its current incarnation, not that straightforward: programs have to be "massaged" by tools that insert intrinsics into the source code, in order to identify the Basic Blocks that the Zero-Overhead Loops can run. Can this be merged into standard gcc and llvm compilers? As intrinsics: of course. Can it become part of auto-vectorization? Probably, if an infinite supply of money and engineering time is thrown at it. Is a half-way-house solution of compiler intrinsics good enough? Intel, ARM, MIPS, Power ISA and RISC-V have all already said "yes" on that, for several decades, and advanced programmers are comfortable with the practice.
Additional questions remain as to whether OpenCAPI or its use for this particular scenario requires that the PEs, even quite basic ones, implement a full RADIX MMU, and associated TLB lookup? In order to ensure that programs may be cleanly and seamlessly transferred between PEs and CPU the answer is quite likely to be "yes", which is interesting in and of itself. Fortunately, the associated L1 Cache with TLB Translation does not have to be large, and the actual RADIX Tree Walk need not explicitly be done by the PEs, it can be handled by the main CPU as a software-extension: PEs generate a TLB Miss notification to the main CPU over OpenCAPI, and the main CPU feeds back the new TLB entries to the PE in response.
Also in practical terms, with the PEs anticipated to be so small as to make running a full SMP-aware OS impractical it will not just be their TLB pages that need remote management but their entire register file including the Program Counter will need to be set up, and the ZOLC Context as well. With OpenCAPI packet formats being quite large a concern is that the context management increases latency to the point where the premise of this paper is invalidated. Research is needed here as to whether a bare-bones microkernel would be viable, or a Management Core closer to the PEs (on the same die or Multi-Chip-Module as the PEs) would allow better bandwidth and reduce Management Overhead on the main CPUs. However if the same level of power saving as Snitch (1/6th) and the same sort of reduction in algorithm runtime as ZOLC (20 to 80%) is not unreasonable to expect, this is definitely compelling enough to warrant in-depth investigation.
Use-case: Matrix and Convolutions

First, some important definitions, because there are two different Vectorization Modes in SVP64:
- Horizontal-First: (aka standard Cray Vectors) walk through elements first before moving to next instruction
- Vertical-First: walk through instructions before
moving to next element. Currently managed by
svstep, ZOLC may be deployed to manage the stepping, in a Deterministic manner.
Second: SVP64 Draft Matrix Multiply is currently set up to arrange a Schedule of Multiply-and-Accumulates, suitable for pipelining, that will, ultimately, result in a Matrix Multiply. Normal processors are forced to perform "loop-unrolling" in order to achieve this same Schedule. SIMD processors are further forced into a situation of pre-arranging rotated copies of data if the Matrices are not exactly on a power-of-two boundary.
The current limitation of SVP64 however is (when Horizontal-First
is deployed, at least, which is the least number of instructions)
that both source and destination Matrices have to be in-registers,
in full. Vertical-First may be used to perform a LD/ST within
the loop, covered by svstep, but it is still not ideal. This
is where the Snitch and EXTRA-V concepts kick in.

Imagine a large Matrix scenario, with several values close to zero that could be skipped: no need to include zero-multiplications, but a traditional CPU in no way can help: only by loading the data through the L1-L4 Cache and Virtual Memory Barriers is it possible to ascertain, retrospectively, that time and power had just been wasted.
SVP64 is able to do what is termed "Vertical-First" Vectorization, combined with SVREMAP Matrix Schedules. Imagine that SVREMAP has been extended, Snitch-style, to perform a deterministic memory-array walk of a large Matrix.
Let us also imagine that the Matrices are stored in Memory with PEs attached, and that the PEs are fully functioning Power ISA with Draft SVP64, but their Multiply capability is not as good as the main CPU. Therefore: we want the PEs to conditionally feed sparse data to the main CPU, a la "Extra-V".
- The ZOLC SVREMAP System running on the main CPU generates a Matrix Memory-Load Schedule.
- The Schedule is sent to the PEs, next to the Memory, via OpenCAPI
- The PEs are also sent the Basic Block to be executed on each Memory Load (each element of the Matrices to be multiplied)
- The PEs execute the Basic Block and exclude, in a deterministic fashion, any elements containing Zero values
- Non-zero elements are sent, via OpenCAPI, to the main CPU, which queues sequences of Multiply-and-Accumulate, and feeds the results back to Memory, again via OpenCAPI, to the PEs.
- The PEs, which are tracking the Sparse Conditions, know where to store the results received
In essence this is near-identical to the original Snitch concept except that there are, like Extra-V, PEs able to perform conditional testing of the data as it goes both to and from the main CPU. In this way a large Sparse Matrix Multiply or Convolution may be achieved without having to pass unnecessary data through L1/L2/L3 Caches only to find, at the CPU, that it is zero.
The reason in this case for the use of Vertical-First Mode is the conditional execution of the Multiply-and-Accumulate. Horizontal-First Mode is the standard Cray-Style Vectorization: loop on all elements with the same instruction before moving on to the next instruction. Horizontal-First Predication needs to be pre-calculated for the entire Vector in order to exclude certain elements from the computation. In this case, that's an expensive inconvenience (remarkably similar to the problems associated with Memory-to-Memory Vector Machines such as the CDC Star-100).
Vertical-First allows scalar instructions and scalar temporary registers to be utilised in the assessment as to whether a particular Vector element should be skipped, utilising a straight Branch instruction (or ZOLC Conditions). The Vertical Vector technique is pioneered by Mitch Alsup and is a key feature of his VVM Extension to MyISA 66000. Careful analysis of the registers within the Vertical-First Loop allows a Multi-Issue Out-of-Order Engine to amortise in-flight scalar looped operations into SIMD batches as long as the loop is kept small enough to entirely fit into in-flight Reservation Stations in the first place.
(With thanks and gratitude to Mitch Alsup on comp.arch for
spending considerable time explaining VVM, how its Loop
Construct explicitly identifies loop-invariant registers,
and how that helps Register Hazards and SIMD amortisation
on a GB-OoO Micro-architecture)
Draft Image (placeholder):

The program being executed is a simple loop with a conditional test that ignores the multiply if the input is zero.
- In the CPU-only case (top) the data goes through L1/L2 Cache before reaching the CPU.
- However the PE version does not send zero-data to the CPU, and even when it does it goes into a Coherent FIFO: no real compelling need to enter L1/L2 Cache or even the CPU Register File (one of the key reasons why Snitch saves so much power).
- The PE-only version (see next use-case) the CPU is mostly idle, serving RADIX MMU TLB requests for PEs, and OpenCAPI requests.
Use-case variant: More powerful in-memory PEs
An obvious variant of the above is that, if there is inherently more parallelism in the data set, then the PEs get their own Multiply-and-Accumulate instruction, and rather than send the data to the CPU over OpenCAPI, perform the Matrix-Multiply directly themselves.
However the source code and binary would be near-identical if not identical in every respect, and the PEs implementing the full ZOLC capability in order to compact binary size to the bare minimum. The main CPU's role would be to coordinate and manage the PEs over OpenCAPI.
One key strategic question does remain: do the PEs need to have a RADIX MMU and associated TLB-aware minimal L1 Cache, in order to support OpenCAPI properly? The answer is very likely to be yes. The saving grace here is that with the expectation of running only hot-loops with ZOLC-driven binaries, the size of each PE's TLB-aware L1 Cache needed would be miniscule compared to the average high-end CPU.
Comparison of PE-CPU to GPU-CPU interaction
The informed reader will have noted the remarkable similarity between how a CPU communicates with a GPU to schedule tasks, and the proposed architecture. CPUs schedule tasks with GPUs as follows:
- User-space program encounters an OpenGL function, in the CPU's ISA.
- Proprietary GPU Driver, still in the CPU's ISA, prepares a Shader Binary written in the GPU's ISA.
- GPU Driver wishes to transfer both the data and the Shader Binary to the GPU. Both may only do so via Shared Memory, usually DMA over PCIe (assuming a PCIe Graphics Card)
- GPU Driver which has been running CPU userspace notifies CPU kernelspace of the desire to transfer data and GPU Shader Binary to the GPU. A context-switch occurs...
It is almost unfair to burden the reader with further details. The extraordinarily convoluted procedure is as bad as it sounds. Hundreds of thousands of tasks per second are scheduled this way, with hundreds or megabytes of data per second being exchanged as well.
Yet, the process is not that different from how things would work with the proposed microarchitecture: the differences however are key.
- Both PEs and CPU run the exact same ISA. A major complexity of 3D GPU and CUDA workloads (JIT compilation etc) is eliminated, and, crucially, the CPU may directly execute the PE's tasks, if needed. This simply is not even remotely possible on GPU Architectures.
- Where GPU Drivers use PCIe Shared Memory, the proposed architecture deploys OpenCAPI.
- Where GPUs are a foreign architecture and a foreign ISA, the proposed architecture only narrowly misses being defined as big/LITTLE Symmetric Multi-Processing (SMP) by virtue of the massively-parallel PEs being a bit light on L1 Cache, in favour of large ALUs and proximity to Memory, and require a modest amount of "helper" assistance with their Virtual Memory Management.
- The proposed architecture has the markup points emdedded into the binary programs where PEs may take over from the CPU, and there is accompanying (planned) hardware-level assistance at the ISA level. GPUs, which have to work with a wide range of commodity CPUs, cannot in any way expect ARM or Intel to add support for GPU Task Scheduling directly into the ARM or x86 ISAs!
On this last point it is crucial to note that SVP64 began its inspiration from a Hybrid CPU-GPU-VPU paradigm (like ICubeCorp's IC3128) and consequently has versatility that the separate specialisation of both GPU and CPU architectures lack.
Roadmap summary of Advanced SVP64
The future direction for SVP64, then, is:
- To overcome its current limitation of REMAP Schedules being restricted to Register Files, leveraging the Snitch-style register interception "tagging" technique.
- To adopt ZOLC and merge REMAP Schedules into ZOLC
- To bring OpenCAPI Memory Access into ZOLC as a first-level concept that mirrors Snitch's Coherent Memory interception
- To add the Graph-Node Walking Capability of Extra-V to ZOLC / SVREMAP
- To make it possible, in a combination of hardware and software, to easily identify ZOLC / SVREMAP Blocks that may be transparently pushed down closer to Memory, for localised distributed parallel execution, by OpenCAPI-aware PEs, exploiting both the Deterministic nature of ZOLC / SVREMAP combined with the Cache-Coherent nature of OpenCAPI, to the maximum extent possible.
- To explore "Remote Management" of PE RADIX MMU, TLB, and Context-Switching (register file transferrance) by proxy, over OpenCAPI, to ensure that the distributed PEs are as close to a Standard SMP model as possible, for programmers.
- To make the exploitation of this powerful solution as simple and straightforward as possible for Software Engineers to use, in standard common-usage compilers, gcc and llvm.
- To propose extensions to Public Standards that allow all of the above to become part of everyday ubiquitous mass-volume computing.
Even the first of these - merging Snitch-style register tagging into SVP64 - would expand SVP64's capability for Matrices, currently limited to around 5x7 to 6x6 Matrices and constrained by the size of the register files (128 64-bit entries), to arbitrary (massive) sizes.
Summary
There are historical and current efforts that step away from both a general-purpose architecture and from the practice of using compiler intrinsics in general-purpose compute to make programmer's lives easier. A classic example being the Cell Processor (Sony PS3) which required programmers to use DMA to schedule processing tasks. These specialist high-performance architectures are only tolerated for as long as there is no equivalent performant alternative that is easier to program.
Combining SVP64 with ZOLC and OpenCAPI can produce an extremely powerful architectural base that fits well with intrinsics embedded into standard general-purpose compilers (gcc, llvm) as a pragmatic compromise which makes it useful right out the gate. Further R&D may target compiler technology that brings it on-par with NVIDIA, Graphcore, AMDGPU, but with intrinsics there is no critical product launch dependence on having such advanced compilers.
Bottom line is that there is a clear roadmap towards solving a long standing problem facing Computer Science and doing so in a way that reduces power consumption reduces algorithm completion time and reduces the need for complex hardware microarchitectures in favour of much smaller distributed coherent Processing Elements with a Heterogenous ISA across the board.
Appendix
Samsung PIM
Samsung's Processing-in-Memory seems to be ready to launch as a commercial product that uses HBM as its Memory Standard, has "some logic suitable for AI", has parallel processing elements, and offers 70% reduction in power consumption and a 2x performance increase in speech recognition. Details beyond that as to its internal workings or programmability are minimal, however given the similarity to D-Matrix and Google TPU it is reasonable to place in the same category.
- Samsung PIM IEEE Article explains that there are 9 instructions, mostly FP16 arithmetic, and that it is designed to "complement" AI rather than compete. With only 9 instructions, 2 of which will be LOAD and STORE, conditional code execution seems unlikely. Silicon area in DRAM is increased by 5% for a much greater reduction in power. The article notes, pointedly, that programmability will be a key deciding factor. The article also notes that Samsung has proposed its architecture as a JEDEC Standard.
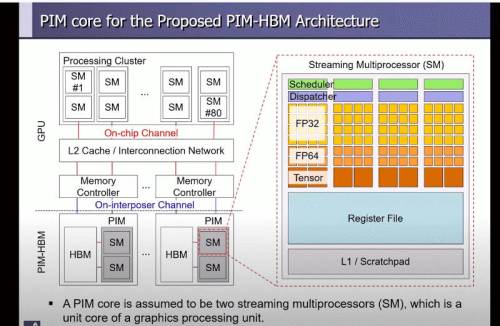
PIM-HBM Research
Presentation by Seongguk Kim and associated video showing 3D-stacked DRAM connected to GPUs, but notes that even HBM, due to large GPU size, is less advantageous than it should be. Processing-in-Memory is therefore logically proposed. the PE (named a Streaming Multiprocessor) is much more sophisticated, comprising Register File, L1 Cache, FP32, FP64 and a Tensor Unit.
etp4hpc.eu
ETP 4 HPC is a European Joint Initiative for HPC, with an eye towards Processing in Memory
Salient Labs
Research paper explaining that they can exceed a 14 ghz clock rate Multiply-and-Accumulate using Photonics.
SparseLNR
SparseLNR restructures sparse tensor computations using loop-nest restructuring.
Additional ZOLC Resources