HDL workflow
This section describes the workflow and some best practices for developing the Libre-SOC hardware. We use nmigen, yosys and symbiyosys, and this page is intended not just to help you get set up, it is intended to help advise you of some tricks and practices that will help you become effective team contributors.
It is particularly important to bear in mind that we are not just "developing code", here: we are creating a "lasting legacy educational resource" for other people to learn from, and for businesses and students alike to be able to use, learn from and augment for their own purposes.
It is also important to appreciate and respect that we are funded under NLNet's Privacy and Enhanced Trust Programme http://nlnet.nl/PET. Full transparency, readability, documentation, effective team communication and formal mathematical proofs for all code at all levels is therefore paramount.
Therefore, we need not only to be "self-sufficient" (absolutely under no circumstances critically reliant on somebody else's servers or protocols) we also need to ensure that everything (including all communication such as the mailing list archives) are recorded, replicable, and accessible in perpetuity. Use of slack or a "forum" either actively prevents or makes that much harder.
Collaboration resources
The main message here: use the right tool for the right job.
- mailing list: general communication and discussion.
- irc channel #libre-soc on irc.libera.chat: real(ish)-time communication.
- bugtracker: task-orientated, goal-orientated focussed discussion.
- ikiwiki: document store, information store, and (editable) main website
- git repositories: code stores (not binary or auto-generated output store)
- ftp server (https://ftp.libre-soc.org/): large (temporary, auto-generated) file store.
Note also the lack of a "forum" in the above list. this is very deliberate. forums are a serious distraction when it comes to technical heavily goal-orientated development. recent internet users may enjoy looking up the "AOL metoo postings" meme.
Note also the complete lack of "social platforms". if we wanted to tell everybody how much better each of us are than anyone else in the team, how many times we made a commit (look at me, look at me, i'm so clever), and how many times we went to the bathroom, we would have installed a social media based project "management" system.
Main contact method: mailing list
To respect the transparency requirements, conversations need to be public and archived (i.e not skype, not telegram, not discord, and anyone seriously suggesting slack will be thrown to the lions). Therefore we have a mailing list. Everything goes through there. https://lists.libre-soc.org/mailman/listinfo/libre-soc-dev therefore please do google "mailing list etiquette" and at the very minimum look up and understand the following:
- This is a technical mailing list with complex topics. Top posting is completely inappropriate. Don't do it unless you have mitigating circumstances, and even then please apologise and explain ("hello sorry using phone at airport flight soon, v. quick reply: ....")
- Always trim context but do not cut excessively to the point where people cannot follow the discussion. Especially do not cut the attribution ("On monday xxx wrote") of something that you are actually replying to.
- Use inline replies i.e. reply at the point in the relevant part of the conversation, as if you were actually having a conversation.
- Follow standard IETF reply formatting, using ">" for cascaded indentation of other people's replies. If using gmail, please: SWITCH OFF RICH TEXT EDITING.
- Please for god's sake do not use "my replies are in a different colour". Only old and highly regarded people still using AOL are allowed to get away with that (such as Mitch).
- Start a new topic with a relevant subject line. If an existing discussion changes direction, change the subject line to reflect the new topic (or start a new conversation entirely, without using the "reply" button)
- DMARC is a pain on the neck. Try to avoid GPG signed messages. sigh.
- Don't send massive attachments. Put them online (no, not on facebook or google drive or anywhere else that demands privacy violations) and provide the link. Which should not require any kind of login to access. ask the listadmin if you don't have anywhere suitable: FTP access can be arranged.
Actionable items from mailing list
If discussions result in any actionable items, it is important not to lose track of them. Create a bugreport, find the discussion in the archives https://lists.libre-soc.org/pipermail/libre-soc-dev/, and put the link actually in the bugtracker as one of the comments.
At some point in any discussion, the sudden realisation may dawn on one or more people that this is an "actionable" discussion. at that point it may become better to use https://bugs.libre-soc.org/ itself to continue the discussion rather than to keep on dropping copies of links into the bugtracker. The bugtracker sends copies of comments to the list however this is 'one-way' (note from lkcl: because this involves running an automated perl script from email, on every email, on the server, that is a high security risk, and i'm not doing it. sorry.)
Mailing list != editable document store
Also, please do not use the mailing list as an "information or document store or poor-man's editor" including not sending large images. We have the wiki for that. Edit a page and tell people what you did (summarise rather than drop the entire contents at the list) and include the link to the page.
Or, if it is more appropriate, commit a document (or source code) into the relevant git repository then look up the link in the gitweb source tree browser and post that (in the bugtracker or mailing list) See https://git.libre-soc.org/
gmail "spam"ifying the list
See https://blog.kittycooper.com/2014/05/keeping-my-mailing-list-emails-out-of-gmails-spam-folder/
Basically it is possible to select any message from the list, create a "filter" (under "More"), and, on the 2nd dialog box, click the "never send this to Spam" option.
Bugtracker
- LibreSOC bug/task process: libresoc bug process
bugzilla. old and highly effective. sign up in the usual way. any problems, ask on the list.
Please do not ask for the project to be transferred to github or other proprietary nonfree service "because it's soooo convenient", as the lions are getting wind and gout from overfeeding on that one.
one.
ikiwiki
Runs the main libre-soc.org site (including this page). effective, stunningly light on resources, and uses a git repository not a database. That means it can be edited offline.
Usual deal: register an account and you can start editing and contributing straight away.
Hint: to create a new page, find a suitable page that would link to it, first, then put the link in of the page you want to create, as if the page already exists. Save that page, and you will find a question mark next to the new link you created. click that link, and it will fire up a "create new page" editor.
Wiki pages are formatted in markdown syntax.
Hint again: the wiki is backed by a git repository. Don't go overboard but at the same time do not be afraid that you might "damage" or "lose" pages. Although it would be a minor pain, the pages can always be reverted or edited by the sysadmins to restore things if you get in a tiz.
Assistance in creating a much better theme greatly appreciated. e.g. http://www.math.cmu.edu/~gautam/sj/blog/20140720-ikiwiki-navbar.html
git
We use git. More on this below. We also use gitolite3 running on a dedicated server. again, it is extremely effective and low resource utilisation. Reminder: lions are involved if github is mentioned.
gitweb is provided which does a decent job. https://git.libre-soc.org/
Git does version control, ie it tracks changes to files so that previous versions can be got back or compared.
Checklist page git checklist
ftp server
https://ftp.libre-soc.org/ is available for storing large files that do not belong in a git repository, if we have (or ever need) any. Images (etc.) if small and appropriate should go into the wiki, however .tgz archives (etc.) and, at some point, binaries, should be on the ftp server.
Ask on the list if you have a file that belongs on the ftp server.
server
As an aside: all this is "old school" and run on a single core 512MB VM with only a 20GB HDD allocation. it costs only 8 GBP per month from mythic-beasts and means that the project is in no way dependent on anyone else - not microsoft, not google, not facebook, not amazon.
We tried gitlab. it didn't go well. please don't ask to replace the above extremely resource-efficient services with it.
Hardware
RAM is the biggest requirement. Minimum 16GB, the more the better (32 or 64GB starts to reach "acceptable" levels. Disk space is not hugely critical: 256GB SSD should be more than adequate. Simulations and FPGA compilations however are where raw processing power is a must. High end Graphics Cards are nonessential.
What is particularly useful is to have hi-res screens (curved is strongly recommended if the LCD is over 24in wide, to avoid eyeballs going "prism" through long term use), and to have several of them: the more the better. Either a DisplayLink UD160A (or more modern variant) or simply using a second machine (lower spec hardware because it will run editors) is really effective.
Also it is really recommended to have a UHD monitor (4k - 3840x2160), or at least 2560x1200. If given a choice, 4:3 aspect ratio is better than 16:9 particularly when using several of them. However, caveat (details below): please when editing do not assume that everyone will have access to such high resolution screens.
Operating System
First install and become familiar with Debian (Ubuntu if you absolutely must) for standardisation cross-team and so that toolchain installation is greatly simplified. yosys in particular warns that trying to use Windows, BSD or MacOS will get you into a world of pain.
Only a basic GUI desktop is necessary: fvwm2, xfce4, lxde are perfectly sufficient (alongside wicd-gtk for network management). Other more complex desktops can be used however may consume greater resources.
editors and editing
Whilst this is often a personal choice, the fact that many editors are GUI based and run full-screen with the entire right hand side and middle and the majority of the left side of the hi-res screen entirely unused and bereft of text leaves experienced developers both amused and puzzled.
At the point where such full-screen users commit code with line lengths well over 160 characters, that amusement quickly evaporates.
Where the problems occur with full-screen editor usage is when a project is split into dozens if not hundreds of small files (as this one is). At that point it becomes pretty much essential to have as many as six to eight files open and on-screen at once, without overlaps i.e. not in hidden tabs, next to at least two if not three additional free and clear terminals into which commands are regularly and routinely typed (make, git commit, nosetests3 etc). Illustrated with the following 3840x2160 screenshot (click to view full image), where every one of those 80x70 xterm windows is relevant to the task at hand.

(hint/tip: fvwm2 set up with "mouse-over to raise focus, rather than additionally requiring a mouse click, can save a huge amount of cumulative development time here, switching between editor terminal(s) and the command terminals).
Once this becomes necessary, it it turn implies that having greater than 80 chars per line - and running editors full-screen - is a severe hinderance to an essential and highly effective workflow technique.
Additionally, care should be taken to respect that not everyone will have 200+ column editor windows and the eyesight of a hawk. They may only have a 1280 x 800 laptop which barely fits two 80x53 xterms side by side. Consequently, having excessively long functions is also a hindrance to others, as such developers with limited screen resources would need to continuously page-up and page-down to read the code even of a single function, in full.
This helps explain in part, below, why compliance with pep8 is enforced, including its 80 character limit. In short: not everyone has the same "modern" GUI workflow or has access to the same computing resources as you, so please do respect that.
More on this concept is here. Note very pointedly that Linus Torvalds specifically states that he does not want Linux kernel development to become the exclusive domain of the "wealthy". That means no to assumptions about access to ultra-high resolution screens.
Software prerequisites
Please make sure if you install manually that you install dependencies in strict order. Failing to adhere to this will result in pip3 downloading unauthorised older software versions. See http://lists.libre-soc.org/pipermail/libre-soc-dev/2021-September/003666.html
Whilst many resources online advocate "sudo" in front of all root-level
commands below, this quickly becomes tiresome. run "sudo bash", get a
root prompt, and save yourself some typing.
- sudo bash
- apt-get install vim exuberant-ctags
- apt-get install build-essential
- apt-get install git python3.7 python3.7-dev python3-nose
- apt-get install graphviz xdot gtkwave
- apt-get install python3-venv
- apt-get install python-virtualenv # this is an alternative to python3-venv
- apt-get install tcl-dev libreadline-dev bison flex libffi-dev iverilog
- return to user prompt (ctrl-d)
(The above assumes that you are running Debian.)
This will get you python3 and other tools that are needed. graphviz is essential for showing the interconnections between cells, and gtkwave is essential for debugging.
If you would like to save yourself a lot more typing, check out the dev-env-setup repository, examine the scripts there and use them to automate much of the process below.
If you would like just to install only the apt dependencies use install-hdl-apt-reqs instead.
This page gives more details and a step by step process : devscripts
git
Look up good tutorials on how to use git effectively. There are so many it is hard to recommend one. This is however essential. If you are not comfortable with git, and you let things stay that way, it will seriously impede development progress.
If working all day you should expect to be making at least two commits per hour, so should become familiar with it very quickly. If you are not doing around 2 commits per hour, something is wrong and you should read the workflow instructions below more carefully, and also ask for advice on the mailing list.
Worth noting: this project does not use branches. All code is committed to master and we require that it be either zero-impact additions or that relevant unit tests pass 100%. This ensures that people's work does not get "lost" or isolated and out of touch due to major branch diversion, and that people communicate and coordinate with each other.
This is not a hard rule: under special circumstances branches can be useful. They should not however be considered "routine".
For guidance on when branches are appropriate, see libresoc bug process.
For advice on commit messages see the Coding section further down on this page.
yosys
Follow the source code (git clone) instructions here, do not use the "stable" version (do not download the tarball): https://github.com/YosysHQ/yosys
Or, alternatively, use the hdl-tools-yosys script (which also installs symbiyosys and its dependencies)
Do not try to use a fixed revision of yosys (currently 0.9), nmigen is evolving and frequently interacts with yosys.
Yosys is a hardware description language. RTL Register Transfer Level models how data moves between registers.
symbiyosys
To install follow the instructions here Once done look at A simple BMC example
You do not have to install all of those (avy, boolector can be left out if desired) however the more that are installed the more effective the formal proof scripts will be (less resource utilisation in certain circumstances).
SymbiYosys (sby) is a front-end driver program for Yosys-based formal hardware verification flows.
nmigen (TM)
nmigen is a registered trademark of M-Labs https://uspto.report/TM/88980893
PLEASE NOTE: it is critical to install nmigen as the first dependency prior to installing any further python-based Libre-SOC HDL repositories. If "pip3 list" shows that nmigen has been auto-installed please remove it
nmigen may be installed as follows:
- mkdir ~/src
- cd !$
- git clone https://gitlab.com/nmigen/nmigen.git
- cd nmigen
- sudo bash
- python3 setup.py develop
- ctrl-d
Testing can then be carried out with "python3 setup.py test"
nmigen is a Python toolbox for building complex digital hardware.
Softfloat and sfpy
These are a test suite dependency for the ieee754fpu library, and will be changed in the future to use Jacob's simple-soft-float library. In the meantime, sfpy can be built as follows:
git clone --recursive https://github.com/billzorn/sfpy.git
cd sfpy
git apply /path/to/ieee754fpu/sfpy.patch
cd SoftPosit
git apply ../softposit_sfpy_build.patch
git apply /path/to/ieee754fpu/SoftPosit.patch
cd ../berkely-softfloat-3
# Note: Do not apply the patch included in sfpy for berkely-softfloat,
# it contains the same changes as this one
git apply /path/to/ieee754fpu/berkeley-softfloat.patch
cd ..
# prepare a virtual environment for building
python3 -m venv .env
# or, if you prefer the old way:
# virtualenv -p python3 .env
# install dependencies
source .env/bin/activate
pip3 install --upgrade -r requirements.txt
# build
make lib -j$(nproc)
make cython
make inplace -j$(nproc)
make wheel
# install
deactivate # deactivates venv, optional
pip3 install dist/sfpy*.whl
You can test your installation by doing the following:
python3
>>> from sfpy import Posit8
>>> Posit8(1.3)
It should print out Posit8(1.3125)
qemu, cross-compilers, gdb
As we are doing POWER ISA, POWER ISA compilers, toolchains and emulators are required. Again, if you want to save yourself some typing, use the dev scripts. install-hdl-apt-reqs script will install the qemu; ppc64-gdb-gcc script will install the toolchain and the corresponding debugger. The steps are provided below only for reference; when in doubt, consider checking and running the scripts.
Install powerpc64 gcc:
apt-get install gcc-8-powerpc64-linux-gnu
Install qemu:
apt-get install qemu-system-ppc
Install gdb from source. Obtain the required tarball matching the version of gcc (8.3) from here https://ftp.gnu.org/gnu/gdb/, unpack it, then:
cd gdb-8.3 (or other location)
mkdir build
cd build
../configure --srcdir=.. --host=x86_64-linux --target=powerpc64-linux-gnu
make -j$(nproc)
make install
gdb lets you debug running programs. qemu emulates processors, you can run programs under qemu.
power-instruction-analyzer (pia)
We have a custom tool built in Rust by programmerjake to help analyze the OpenPower instructions' execution on actual hardware.
Install Rust:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Make sure we have the correct and up-to-date rust compiler (rustc & cargo):
rustup default stable
rustup update
Install the Python extension from git source by doing the following:
git clone https://salsa.debian.org/Kazan-team/power-instruction-analyzer.git pia
cd pia
./libre-soc-install.sh
Chips4Makers JTAG
As this is an actual ASIC, we do not rely on an FPGA's JTAG TAP interface, instead require a full complete independent implementation of JTAG. Staf Verhaegen has one, with a full test suite, and it is superb and well-written. The Libre-SOC version includes DMI (Debug Memory Interface):
git clone https://git.libre-soc.org/git/c4m-jtag.git/
cd c4m-jtag
python3 setup.py develop
Included is an IDCODE tap point, Wishbone Master (for direct memory read and write, fully independent of the core), IOPad redirection and testing, and general purpose shift register capability for any custom use.
We added a DMI to JTAG bridge in LibreSOC which is directly connected to the core, to access registers and to be able to start and stop the core and change the PC. In combination with the JTAG Wishbone interface the test ASIC can have a bootloader uploaded directly into onboard SRAM and execution begun.
Chips4Makers make it possible for makers and hobbyists to make their own open source chips.
JTAG (Joint Test Action Group) is an industry standard for verifying designs and testing printed circuit boards after manufacture.
The Wishbone bus is an open source hardware computer bus intended to let the parts of an integrated circuit communicate with each other.
Coriolis2
See coriolis2 page, for those people doing layout work.
Nextpnr
A portable FPGA place and route tool.
See nextpnr page for installation instructions of nextpnr with ECP5 support for Lattice FPGA ECP5 series. Also see ECP5 FPGA for connecting up to JTAG with a ULX3S and the Lattice VERSA_ECP5.
Nextpnr-xilinx
An open source place and route framework for Xilinx FPGAs using Project Xray. We will use it for Xilinx 7-series FPGAs like Artix-7.
One of the ways to get Arty A7 100t Digilent FPGA board working.
See nextpnr-xilinx for installation instructions and dependencies.
Verilator
The fastest Verilog and SystemVerilog simulator. It compiles Verilog to C++ or SystemC.
Advise use only v4.106 at the moment.
See verilator page for installation instructions.
GHDL
GHDL is a shorthand for G Hardware Design Language. It is a VHDL analyzer, compiler, simulator and (experimental) synthesizer that can process (nearly) any VHDL design.
VHDL is an acronym for Very High Speed Integrated Circuit (VHSIC) Hardware Description Language (HDL), which is a programming language used to describe a logic circuit by function, data flow behavior, or structure.
Unlike some other simulators, GHDL is a compiler: it directly translates a VHDL file to machine code, without using an intermediary language such as C or C++. Therefore, the compiled code should be faster and the analysis time should be shorter than with a compiler using an intermediary language.
GHDL aims at implementing VHDL as defined by IEEE 1076. It supports the 1987, 1993 and 2002 revisions and, partially, 2008. PSL is also partially supported.
See ghdl page for installation instructions.
Icarus Verilog
Icarus Verilog is a Verilog simulation and synthesis tool. It operates as a compiler, compiling source code written in Verilog (IEEE-1364) into some target format.
See iverilog page for installation instructions.
Cocotb
cocotb is a COroutine based COsimulation TestBench environment for verifying VHDL and SystemVerilog RTL using Python.
See cocotb page for installation instructions.
Symbiflow
A fully open source toolchain for the development of FPGAs. Currently it targets Xilinx 7-series, Lattice iCE40 and ECP5, Quicklogic EOS S3.
One way to get the Arty A7 100t Digilent FPGA board working.
See symbiflow for installation instructions and dependencies.
FPGA/Board Boot-Loaders-Programmers
Open source FPGA/Board boot-loaders and programmers for ULX3S, ECP5 and OrangeCrab.
Currently these programs dfu-util, openFPGALoader, ujprog, fujprog, xc3sprog and ecpprog are going to be used.
See fpga-boot-loaders-progs for installation instructions and dependencies.
ls2 peripheral fabric
Registering for git repository access
After going through the onboarding process and having agreed to take
responsibility for certain tasks, ask on the mailing list for git
repository access, sending in a public key (id_rsa.pub). If you do
not have one then generate it with ssh-keygen -t rsa. You will find it
in ~/.ssh
NEVER SEND ANYONE THE PRIVATE KEY. By contrast the public key, on account of being public, is perfectly fine to make... err... public.
Create a file ~/.ssh/config with the following lines:
Host git.libre-soc.org
Port 922
Test that you have access with this command:
ssh -v -p922 gitolite3@git.libre-soc.org
Please note: DO NOT TYPE A PASSWORD - the server gets hit by a lot of port-scanning, and detection of password failures are used to instantly ban IP addresses.
Wait for the Project Admin to confirm that the ssh key has been added to the required repositories. Once confirmed, you can clone any of the repos at https://git.libre-soc.org/:
git clone gitolite3@git.libre-soc.org:REPONAME.git
Alternatively, the .ssh/config can be skipped and this used:
git clone ssh://gitolite3@git.libre-soc.org:922/REPONAME.git
Note: DO NOT ATTEMPT TO LOG IN TO THE SERVER WITH A PERSONAL ACCOUNT. fail2ban is running and, due to repeated persistent port-scanning spammers is set up to instantly ban any unauthorised ssh access for up to two weeks. This keeps log file sizes down on the server (which is resource-constrained). If you are wondering why this is done, it's a lot of port-scans.
Therefore, only ssh in to server with the gitolite3 account, only on port 922, and only once the systems administrator has given you the all-clear that the ssh key has been added.
git configuration
Although there are methods online which describe how (and why) these settings are normally done, honestly it is simpler and easier to open ~/.gitconfig and add them by hand.
core.autocrlf is a good idea to ensure that anyone adding DOS-formatted files they don't become a pain. pull.rebase is something that is greatly preferred for this project because it avoids the mess of "multiple extra merge git tree entries", and branch.autosetuprebase=always will, if you want it, always ensure that a new git checkout is set up with rebase.
[core]
autocrlf = input
[push]
default = simple
[pull]
rebase = true
[branch]
autosetuprebase = always
Checking out the HDL repositories
Before running the following, install the dependencies. This is easiest done with this script https://git.libre-soc.org/?p=dev-env-setup.git;a=blob;f=install-hdl-apt-reqs;hb=HEAD
It is critically important to install these in STRICT order, otherwise pip3 interferes and performs unauthorised downloads without informing you of what it is doing.
- mkdir ~/src
- cd !$
- git clone https://gitlab.com/nmigen/nmigen
- git clone https://gitlab.com/nmigen/nmigen-boards
- git clone https://gitlab.com/nmigen/nmigen-soc
- git clone https://gitlab.com/nmigen/nmigen-stdio
- git clone gitolite3@git.libre-soc.org:c4m-jtag.git
- git clone gitolite3@git.libre-soc.org:nmutil.git
- git clone gitolite3@git.libre-soc.org:openpower-isa.git
- git clone gitolite3@git.libre-soc.org:ieee754fpu.git
- git clone gitolite3@git.libre-soc.org:soc.git
In each of these directories, in the order listed, track down the
setup.py file, then, as root (sudo bash), run the following:
- python3 setup.py develop
The reason for using "develop" mode is that the code may be edited in-place yet still imported "globally". There are variants on this theme for multi-user machine use however it is often just easier to get your own machine these days.
The reason for the order is because soc depends on ieee754fpu, and ieee754fpu depends on nmutil. If you do not follow the listed order pip3 will go off and download an arbitrary version without your consent.
If "python3 setup.py install" is used it is a pain: edit, then
install. edit, then install. It gets extremely tedious, hence why
"develop" was created.
If you prefer you can use this script instead: of course you checked it in advance and accept full responsibility. https://git.libre-soc.org/?p=dev-env-setup.git;a=blob;f=hdl-dev-repos;hb=HEAD
Development Rules
Team communication:
- new members, add yourself to the about us page and create yourself a home page using someone else's page as a template.
- communicate on the mailing list or the bugtracker an intent to take responsibility for a particular task.
- assign yourself as the bug's owner
- keep in touch about what you are doing, and why you are doing it.
- edit your home page regularly, particularly to track tasks so that they can be paid by NLNet.
- if you cannot do something that you have taken responsibility for, then unless it is a dire personal emergency please say so, on-list. we won't mind. we'll help sort it out.
Regarding the above it is important that you read, understand, and agree to the charter because the charter is about ensuring that we operate as an effective organisation. It's not about "setting rules and meting out punishment".
Coding
for actual code development
Copyright Notices
All code must have copyright and grant notices (where work was done under budget).
Breakdown of the header in the above example:
- Code was worked on by Jacob Lifshay during 2022.
- Work was done under LibreSOC's Crypto Router
grant submitted to NLnet.
NLnet grant code is
2021-02-052. - The NLnet grant was under the NLnet Assure fund.
- Financial support for NGI Assure comes from European Commission's Next Generation Internet Programme, grant agreement no. 957073.
Template:
# SPDX-License-Identifier: LGPL-3-or-later
# Copyright 202X [Name] [email]
#
# Funded by NLnet [Programme Name] Programme [202X-YY-ZZZ], [NLnet URL] part
# of [EU Programme Name] 202X EU Programme [Programme Number].
Plan unit tests
- plan in advance to write not just code but a full test suite for that code. this is not optional. large python projects that do not have unit tests FAIL (see separate section below).
- Prioritise writing formal proofs and a single clear unit test that is more like a "worked example". We receive NLNet funds for writing formal proofs, plus they cover corner cases and take far less time to write
Commit tested or zero-dependent code
- only commit code that has been tested (or is presently unused). other people will be depending on you, so do take care not to screw up. not least because, as it says in the charter it will be your responsibility to fix. that said, do not feel intimidated: ask for help and advice, and you'll get it straight away.
Commit often
- commit often. several times a day, and "git push" it. this is collaboration. if something is left even overnight uncommitted and not pushed so that other people can see it, it is a red flag.
- if you find yourself thinking "i'll commit it when it's finished" or "i don't want to commit something that people might criticise" this is not collaboration, it is making yourself a bottleneck. pair-programming is supposed to help avoid this kind of thing however pair-programming is difficult to organise for remote collaborative libre projects (suggestions welcomed here)
Enable editor auto-detection of file changes by external programs
This is important. "git pull" will merge in changes. If you then
arbitrarily save a file without re-loading it, you risk destroying
other people's work.
You can avoid damaging the repositories by following some simple procedures:
run appropriate unit tests
git pull
run appropriate unit tests again (checks other people's work)
git diff # and actually read and review the output
git status # check for any missing files
git commit # with appropriate arguments and message
git push # always always always do this
Absolutely no auto-generated output
- do not commit autogenerated output. write a shell script and commit
that, or add a
Makefileto run the command that generates the output, but do not add the actual output of any command to the repository. ever. this is really important. even if it is a human-readable file rather than a binary object file. - it is very common to add PDFs (the result of running
latex2pdf) or configure.in (the result of runningautomake), they are an absolute nuisance and interfere hugely with git diffs, as well as waste hard disk space and network bandwidth. don't do it. - do not add multi-megabyte or multi-gigabyte "test data". use shell scripts and commit that, which automatically downloads the "test data" from a well-known known-good reliable location instead.
Write commands that do tasks and commit those
- if the command needed to create any given autogenerated output is not currently in the list of known project dependencies, first consult on the list if it is okay to make that command become a hard dependency of the project (hint: java, node.js php and .NET commands may cause delays in response time due to other list participants laughing hysterically), and after a decision is made, document the dependency and how its source code is obtained and built (hence why it has to be discussed carefully)
- if you find yourself repeating commands regularly, chances are high
that someone else will need to run them, too. clearly this includes
yourself, therefore, to make everyone's lives easier including your own,
put them into a
.shshell script (and/or aMakefile), commit them to the repository and document them at the very minimum in the README, INSTALL.txt or somewhere in a docs folder as appropriate. if unsure, ask on the mailing list for advice.
Keep commits single-purpose
- edit files making minimal single purpose modifications (even if it involves multiple files. Good extreme example: globally changing a function name across an entire codebase is one purpose, one commit, yet hundreds of files. miss out one of those files, requiring multiple commits, and it actually becomes a nuisance).
Run unit tests prior to commits
- prior to committing make sure that relevant unit tests pass, or that the change is a zero-impact addition (no unit tests fail at the minimum)
Do not break existing code
- keep working code working at all times. find ways to ensure that this is the case. examples include writing alternative classes that replace existing functionality and adding runtime options to select between old and new code.
Small commits with relevant commit message
- commit no more than around 5 to 10 lines at a time, with a CLEAR message (no "added this" or "changed that").
- if as you write you find that the commit message involves a list of changes or the word "and", then STOP. do not proceed: it is a "red flag" that the commit has not been properly broken down into separate-purpose commits. ask for advice on-list on how to proceed.
Git commit message format
LibreSOC message format based on description given in bug #1126#c40:
- Every commit MUST start with a short title, up to 50 characters.
- The commit title MUST contain either subsystem, or a file path, or a subsystem/path, or a subsystem/subsubsystem combination, which got modified or introduced, and a short summary. These parts must be separated by the colon.
- A good rule is to imagine that the short message begins with "if this patch is applied, it will". For example, a good title is "X: update Y", not "updated Y in X".
- After the title, there must be an empty line, which documents the changes. The limit is 72 characters per line.
- The long description can be omitted if the short description provides enough information or if the commit itself is simple enough.
Example:
subsystem/file.py: document usage
Here goes the long description, which explains everything. First of all,
we stick to limit of 72 characters. Then, perhaps, we'd like to explain
the rationale in more details.
It is suggested to stick to common sense whenever choosing subsystem names or files or long descriptions.
Primary concerns are:
- short titles
- short summaries
- wording for the first line
The rest is up for the committers.
Exceptions to small commit: atomic single purpose commit
- if it is essential to commit large amounts of code, ensure that it is not in use anywhere by any other code. then make a small (single purpose) followup commit which actually puts that code into use.
This last rule is kinda flexible, because if you add the code and add the unit test and added it into the main code and ran all relevant unit tests on all cascade-impacted areas by that change, that's perfectly fine too. however if it is the end of a day, and you need to stop and do not have time to run the necessary unit tests, do not commit the change which integrates untested code: just commit the new code (only) and follow up the next day after running the full relevant unit tests.
Why such strict rules?
The reason for all the above is because python is a dynamically typed language. make one tiny change at the base level of the class hierarchy and the effect may be disastrous.
It is therefore worth reiterating: make absolutely certain that you only commit working code or zero-impact code.
Therefore, if you are absolutely certain that a new addition (new file, new class, new function) is not going to have any side-effects, committing it (a large amount of code) is perfectly fine.
As a general rule, however, do not use this an an excuse to write code first then write unit tests as an afterthought. write less code in conjunction with its (more basic) unit tests, instead. then, folliw up with additions and improvements.
The reason for separating out commits to single purpose only becomes obvious (and regretted if not followed) when, months later, a mistake has to be tracked down and reverted. if the commit does not have an easy-to-find message, it cannot even be located, and once found, if the commit confuses several unrelated changes, not only the diff is larger than it should be, the reversion process becomes extremely painful.
PHP-style python format-strings
As the name suggests, "PHP-style" is not given as a compliment. Format-strings - `f"{variable} {pythoncodefragment}" are a nightmare to read. The lesson from PHP, Zope and Plone: when code is embedded, the purpose of the formatting - the separation of the format from the data to be placed in it - is merged, and consequently become unreadable.
By contrast, let us imagine a situation where 12 variables need to be inserted into a string, four of which are the same variablename:
x = "%s %s %s %s %s %s %s %s %s %s %s %s" % (var1, var2, var3,
var3, var4, var2,
var1, var9, var1,
var3, var4, var1)
This is just as unreadable, but for different reasons. Here it is useful to do this as:
x = f"{var1} {var2} {var3}" \
...
f"{var3} {var4} {var1}"
As a general rule, though, format-specifiers should be strongly avoided, given that they mix even variable-names directly inside a string.
This additionally gives text editors (and online web syntax highlighters) the opportunity to colour syntax-highlight the ASCII string (the format) from the variables to be inserted into that format. gitweb for example (used by this project) cannot highlight string-formatted code.
It turns out that colour is processed by the opposite hemisphere of the brain from written language. Thus, colour-syntax-highlighting is not just a "nice-to-have", it's vital for easier and faster identification of context and an aid to rapid understanding.
Anything that interferes with that - such as python format-strings - has to take a back seat, regardless of its perceived benefits.
If you absolutely must use python-format-strings, only do so by restricting to variables. Create temporary variables if you have to.
y = '/'.join(a_list)
x = f"{y}"
PEP8 format
- all code needs to conform to pep8. use either pep8checker or better run autopep8. however whenever committing whitespace changes, make a separate commit with a commit message "whitespace" or "autopep8 cleanup".
- pep8 REQUIRES no more than 80 chars per line. this is non-negotiable. if you think you need greater than 80 chars, it fundamentally indicates poor code design. split the code down further into smaller classes and functions.
Docstring checker
- TBD there is a docstring checker. at the minimum make sure to have an SPD license header, module header docstring, class docstring and function docstrings on at least non-obvious functions.
Clear code commenting and docstrings
- make liberal but not excessive use of comments. describe a group of lines of code, with terse but useful comments describing the purpose, documenting any side-effects, and anything that could trip you or other developers up. unusual coding techniques should definitely contain a warning.
Only one class per module (ish)
- unless they are very closely related, only have one module (one class) per file. a file only 25 lines long including imports and docstrings is perfectly fine however don't force yourself. again, if unsure, ask on-list.
File and Directory hierarchy
- keep files short and simple. see below as to why
- create a decent directory hierarchy but do not go mad. ask for advice if unsure
No import star!
- please do not use "from module import *". it is extremely bad practice, causes unnecessary resource utilisation, makes code readability and tracking extremely difficult, and results in unintended side-effects.
Example: often you want to find the code from which a class was imported. nirmally you go to the top of the file, check the imports, and you know exactly which file has the class because of the import path. by using wildcards, you have absolutely no clue which wildcard imported which class or classes.
Example: sometimes you may accidentally have duplicate code maintained in two or more places. editing one of them you find, puzzlingly, that the code behaves in some files with the old behaviour, but in others it works. after a massive amount of investigation, you find that the working files happen to have a wildcard import of the newer accidental duplicate class after the wildcard import of the older class with exactly the same name. if you had used explicit imports, you would have spotted the double import of the class from two separate locations, immediately.
Really. don't. use. wildcards.
More about this here:
Keep file and variables short but clear
- try to keep both filenames and variable names short but not ridiculously obtuse. an interesting compromise on imports is "from ridiculousfilename import longsillyname as lsn", and to assign variables as well: "comb = m.d.comb" followed by multiple "comb += nmigen_stmt" lines is a good trick that can reduce code indentation by 6 characters without reducing clarity.
Additionally, use comments just above an obtuse variable in order to help explain what it is for. In combination with keeping the the module itself short, other readers will not need to scroll back several pages in order to understand the code.
Yes it is tempting to actually use the variables as self-explanatory-comments and generally this can be extremely good practice. the problem comes when the variable is so long that a function with several parameters csn no longer fit on a single line, and takes up five to ten lines rather than one or two. at that point, the length of the code is adversely affected and thus so is readability by forcing readers to scroll through reams of pages.
It is a tricky balance: basically use your common sense, or just ask someone else, "can you understand this code?"
Reasons for code structure
Regarding code structure: we decided to go with small modules that are both easy to analyse, as well as fit onto a single page and be readable when displayed as a visual graph on a full UHD monitor. this is done as follows:
- using the capability of nmigen (TODO crossref to example) output the module to a yosys ilang (.il) file
- in a separate terminal window, run yosys
- at the yosys prompt type "read_ilang modulename.il"
- type "show top" and a graphviz window should appear. note that typing show, then space, then pressing the tab key twice will give a full list of submodules (one of which will be "top")
You can now fullsize the graphviz window and scroll around. if it looks reasonably obvious at 100% zoom, i.e the connections can be clearly related in your mind back to the actual code (by matching the graph names against signals and modules in the original nmigen code) and the words are not tiny when zoomed out, and connections are not total incomprehensible spaghetti, then congratulations, you have well-designed code. If not, then this indicates a need to split the code further into submodules and do a bit more work.
The reasons for doing a proper modularisation job are several-fold:
- firstly, we will not be doing a full automated layout-and-hope using alliance/coriolis2, we will be doing leaf-node thru tree node half-automated half-manual layout, finally getting to the floorplan, then revising and iteratively adjusting.
- secondly, examining modules at the gate level (or close to it) is just good practice. poor design creeps in by not knowing what the tools are actually doing (word to experienced developers: yes, we know that the yosys graph != final netlist).
- thirdly, unit testing, particularly formal proofs, is far easier on small sections of code, and complete in a reasonable time.
Special warning / alert to vim users!
Some time around the beginning of 2019 some bright spark decided that an "auto-recommend-completion-of-stuff" option would be a nice, shiny idea to enable by default from that point onwards.
This incredibly annoying "feature" results in tabs (or spaces) being inserted "on your behalf" when you press return on one line, for your "convenience" of not needing to type lots of spaces/tabs just to get to the same indentation level.
Of course, this "feature", if you press return on one line in edit mode and then press "escape", leaves a bundle-of-joy extraneous whitespace exactly where you don't want it, and didn't ask for it, pooped all over your file.
Therefore, please: before running "git commit", get into the habit of always running "git diff", and at the very minimum speed-skim the entire diff, looking for tell-tale "red squares" (these show up under bash diff colour-syntax-highlighting) that inform you that, without your knowledge or consent, vim has "helpfully" inserted extraneous whitespace.
Remove them before git committing because they are not part of the actual desired code-modifications, and committing them is a major and constant distraction for reviewers about actual important things like "the code that actually usefully was modified for that commit"
This has the useful side-effect of ensuring that, right before the commit, you've got the actual diff right in front of you in the xterm window, on which you can base the "commit message".
Unit tests
For further reading, see the wikipedia page on Test-driven Development
This deserves its own special section. It is extremely important to appreciate that without unit tests, python projects are simply unviable. Python itself has over 25,000 individual tests.
This can be quite overwhelming to a beginner developer, especially one used to writing scripts of only 100 lines in length.
Thanks to Samuel Falvo we learned that writing unit tests as a formal proof is not only shorter, it's also far more readable and also, if written properly, provides 100% coverage of corner-cases that would otherwise be overlooked or require tens to hundreds of thousands of tests to be run.
No this is not a joke or even remotely hypothetical, this is an actual real-world problem.
The ieee754fpu requires several hundreds of thousands of tests to be run (currently needing several days to run them all), and even then we cannot be absolutely certain that all possible combinations of input have been tested. With 2128 permutations to try with 2 64 bit FP numbers it is simply impossible to even try.
This is where formal proofs come into play.
Samuel illustrated to us that "ordinary" unit tests can then be written to augment the formal ones, serving the purpose of illustrating how to use the module, more than anything.
However it is appreciated that writing formal proofs is a bit of a black art. This is where team collaboration particularly kicks in, so if you need help, ask on the mailing list.
Don't comment out unit tests: add them first (as failures) and fix code later
Unit tests serve an additional critical purpose of keeping track of code that needs to be written. In many cases, you write the unit test first, despite knowing full well that the code doesn't even exist or is completely broken. The unit test then serves as a constant and important reminder to actually fix (or write) the code.
Therefore, do not comment out unit tests just because they "don't work". If you absolutely must stop a unit test from running, do not delete it. Simply mark it with an appropriate "skip" decorator, preferably with a link to a URL in the bugtracker with further details as to why the unit test should not be run.
Liskov Substitution Principle
Copying from Wikipedia:
The Liskov substitution principle (LSP) is a particular definition of a
subtyping relation, called strong behavioral subtyping, that was initially
introduced by Barbara Liskov in a 1987 conference keynote address titled
Data abstraction and hierarchy. It is based on the concept of
"substitutability" - a principle in object-oriented programming stating
that an object (such as a class) may be replaced by a sub-object (such as
a class that extends the first class) without breaking the program.
It is a semantic rather than merely syntactic relation, because it intends
to guarantee semantic interoperability of types in a hierarchy, object
types in particular.
To paraphrase: an original object/class may be replaced with another object (whose class extends the first class) without breaking the program.
Python is a programming language which makes using LSP pretty straightforward.
In LibreSOC, we aim to follow this principle whenever possible and (bearing time and budget constraints).
(Luke, please include some examples from LibreSOC source here)
Principle of Least Astonishment/Surprise (POLA)
- Example shown by Luke on comment #33 bug #1039
- Wikipedia entry
- Example answer on software eng. stack exchange
Wikipedia mentions that the origin of the term "Principle of Least Astonishment" (or Surprise) comes from a PL/I programming language bulletin board from 1957:
For those parts of the system which cannot be adjusted to the peculiarities
of the user, the designers of a systems programming language should obey
the "Law of Least Astonishment." In short, this law states that every construct
in the system should behave exactly as its syntax suggests. Widely accepted
conventions should be followed whenever possible, and exceptions to previously
established rules of the language should be minimal.
If a method name has a prefix test_ it should be a unit test (or some other
test which is there to check the functionality of a given feature).
A method/function (or attributes/variables, etc.) shouldn't be given a name which is wildly different from the what the user would expect it to do.
Andrey: One example which may meet this rule is TestIssuer,
which is the FSM-based nMigen HDL CPU core used by LibreSOC (so far).
It is so called because it is used to issue unit tests (while also
being synthesisable). This name was however was initially confusing
to me, because my background is in hardware not software engineering.
Task management guidelines
- New guide for RfP submission (in-progress): rfp submission guide
(This section needs to be compared with libresoc bug process)
- Create the task in appropriate "Product" section with appropriate "Component" section. Most code tasks generally use "Libre-SOC's first SOC".
- Fill in "Depends on" and "Blocks" section whenever appropriate. Also add as many related ("See Also") links to other bugreports as possible. bugreports are never isolated.
- Choose the correct task for a budget allocation. Usually the parent task is used.
- Choose the correct NLnet milestone. The best practice is to check the parent task for a correct milestone.
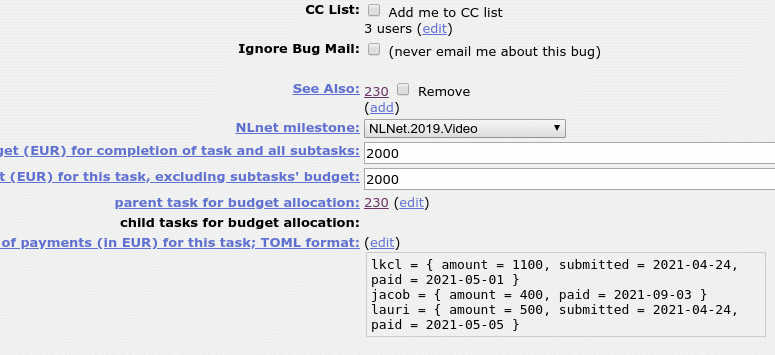
- Assign the budget to the task in
"USER=SUM"form, where "USER" corresponds to your username and "SUM" corresponds to the actual budget in EUR. There may be multiple users. - When the task is completed, you can begin writing an RFP. DO NOT submit it without explicit authorisation and review. Leave out your bank and personal address details if you prefer when sending to the Team Manager for review.
- Once the RFP is written, notify the Team Manager and obtain their explicit approval to send it.
- Once approval is received and the RFP sent, update the
"USER=SUM"field to include the submitted date:"USER={amount=SUM, submitted=SDATE}". The SDATE is entered inYYYY-MM-DDform. - Once the task is paid, again notify the Team Manager (IRC is fine),
and update
"USER={amount=SUM, submitted=SDATE}"to"USER={amount=SUM, submitted=SDATE, paid=PDATE}". The PDATE is entered inYYYY-MM-DDform, too.
Throughout all of this you should be using budget-sync to check the database consistency https://git.libre-soc.org/?p=utils.git;a=blob;f=README.txt;hb=HEAD
TODO Tutorials
Find appropriate tutorials for nmigen and yosys, as well as symbiyosys.
- Robert Baruch's nmigen tutorials look really good: https://github.com/RobertBaruch/nmigen-tutorial
- Although a verilog example this is very useful to do https://symbiyosys.readthedocs.io/en/latest/quickstart.html#first-step-a-simple-bmc-example
- This tutorial looks pretty good and will get you started https://web.archive.org/web/20210123052724/http://blog.lambdaconcept.com/doku.php?id=nmigen:nmigen_install and walks not just through simulation, it takes you through using gtkwave as well.
- There exist several nmigen examples which are also executable https://gitlab.com/nmigen/nmigen/tree/master/examples/ exactly as described in the above tutorial (python3 filename.py -h)
- More nmigen tutorials at ?learning nmigen