- Implementation Log
- bitmanipulation
- Draft Opcode tables
- binary and ternary bitops
- int ops
- shift-and-add
- bitmask set
- grevlut
- xperm
- bitmatrix
- Introduction to Carry-less and GF arithmetic
- Instructions for Carry-less Operations
- Instructions for Binary Galois Fields GF(2^m)
- Instructions for Prime Galois Fields GF(p)
- Already in POWER ISA or subsumed
- Appendix
Implementation Log
- ternlogi https://bugs.libre-soc.org/show_bug.cgi?id=745
- grev https://bugs.libre-soc.org/show_bug.cgi?id=755
- GF2M https://bugs.libre-soc.org/show_bug.cgi?id=782
- binutils https://bugs.libre-soc.org/show_bug.cgi?id=836
- shift-and-add https://bugs.libre-soc.org/show_bug.cgi?id=968
bitmanipulation
DRAFT STATUS
pseudocode: bitmanip
this extension amalgamates bitmanipulation primitives from many sources, including RISC-V bitmanip, Packed SIMD, AVX-512 and OpenPOWER VSX. Also included are DSP/Multimedia operations suitable for Audio/Video. Vectorization and SIMD are removed: these are straight scalar (element) operations making them suitable for embedded applications. Vectorization Context is provided by sv.
When combined with SV, scalar variants of bitmanip operations found in VSX are added so that the Packed SIMD aspects of VSX may be retired as "legacy" in the far future (10 to 20 years). Also, VSX is hundreds of opcodes, requires 128 bit pathways, and is wholly unsuited to low power or embedded scenarios.
ternlogv is experimental and is the only operation that may be considered a "Packed SIMD". It is added as a variant of the already well-justified ternlog operation (done in AVX512 as an immediate only) "because it looks fun". As it is based on the LUT4 concept it will allow accelerated emulation of FPGAs. Other vendors of ISAs are buying FPGA companies to achieve similar objectives.
general-purpose Galois Field 2M operations are added so as to avoid huge custom opcode proliferation across many areas of Computer Science. however for convenience and also to avoid setup costs, some of the more common operations (clmul, crc32) are also added. The expectation is that these operations would all be covered by the same pipeline.
note that there are brownfield spaces below that could incorporate some of the set-before-first and other scalar operations listed in mv.swizzle, vector ops, int fp mv and the av opcodes as well as setvl, svstep, remap
Useful resource:
- https://en.wikiversity.org/wiki/Reed%E2%80%93Solomon_codes_for_coders
- https://maths-people.anu.edu.au/~brent/pd/rpb232tr.pdf
- https://gist.github.com/animetosho/d3ca95da2131b5813e16b5bb1b137ca0
- https://github.com/HJLebbink/asm-dude/wiki/GF2P8AFFINEINVQB
Draft Opcode tables
two major opcodes are needed
PO5 (temporary)
| 26-28 | 29.30 | 31 | name | Form |
|---|---|---|---|---|
| 0 0 | Rc | ternlogi | TLI-Form | |
| 0 0 0 | 0 1 | crfternlogi | CRB-Form | |
| 0 0 1 | 0 1 | rsvd | rsvd | |
| 0 1 / | 0 1 | / | svshape4 | SVI2-Form |
| 1 0 n | 0 1 | rsvd | rsvd | |
| 1 1 n | 0 1 | rsvd | rsvd | |
| 1 iv | 1 | grevlogi | TLI-Form | |
| 0 n n | 1 0 | 0 | madd/sub | A-Form |
| 1 1 | 0 | crternlogi | TLI-Form |
madd/sub:
| 0.5 | 6.10 | 11.15 | 16.20 | 21..25 | 26....30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|
| NN | RT | RA | RB | RC | / 00 10 | 0 | maddsubrs | A-Form |
| NN | RT | RA | RB | RC | / 01 10 | 0 | maddrs | A-Form |
| NN | RT | RA | RB | RC | / 10 10 | 0 | msubrs | A-Form |
PO22 - 2nd major opcode for other bitmanip: minor opcode allocation
| 28.30 | 31 | name |
|---|---|---|
| -00 | 0 | xpermi |
| -00 | 1 | binary lut |
| -01 | 0 | grevlog |
| -01 | 1 | swizzle mv/fmv |
| 010 | Rc | bitmask |
| 011 | SVP64 | |
| 110 | Rc | 1/2-op |
| 111 | bmrevi |
minmax is allocated to PO 19 XO 000011
1-op and variants
| dest | src1 | subop | op |
|---|---|---|---|
| RT | RA | .. | bmatflip |
2-op and variants
| dest | src1 | src2 | subop | op |
|---|---|---|---|---|
| RT | RA | RB | or | bmatflip |
| RT | RA | RB | xor | bmatflip |
| RT | RA | RB | grev | |
| RT | RA | RB | clmul* | |
| RT | RA | RB | gorc | |
| RT | RA | RB | shuf | shuffle |
| RT | RA | RB | unshuf | shuffle |
| RT | RA | RB | width | xperm |
| RT | RA | RB | MMM | minmax |
| RT | RA | RB | av abs avgadd | |
| RT | RA | RB | type | vmask ops |
| RT | RA | RB | type | abs accumulate (overwrite) |
3 ops
- grevlog[w]
- GF mul-add
- bitmask-reverse
TODO: convert all instructions to use RT and not RS
| 0.5 | 6.10 | 11.15 | 16.20 | 21..25 | 26....30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|
| NN | RT | RA | it/im57 | im0-4 | 0 00 00 | 0 | xpermi | TODO-Form |
| NN | - 10 00 | 0 | svshape3 | rsvd | ||||
| NN | - 11 00 | 0 | svshape4 | rsvd | ||||
| NN | RT | RA | RB | RC | nh 00 00 | 1 | binlut | VA-Form |
| NN | RT | RA | RB | /BFA/ | 0 01 00 | 1 | bincrflut | VA-Form |
| NN | 1 01 00 | 1 | svindex | SVI-Form | ||||
| NN | RT | RA | RB | mode | L 10 00 | 1 | bmask | BM2-Form |
| NN | 0 11 00 | 1 | svshape | SVM-Form | ||||
| NN | 1 11 00 | 1 | svremap | SVRM-Form | ||||
| NN | RT | RA | RB | im0-4 | im5-7 01 | 0 | grevlog | TLI-Form |
| NN | - -- 01 | 1 | swizzle mv/f | TODO | ||||
| NN | RT | RA | RB | RC | mode 010 | Rc | bitmask* | VA2-Form |
| NN | FRS | d1 | d0 | d0 | 00 011 | d2 | fmvis | DX-Form |
| NN | FRS | d1 | d0 | d0 | 01 011 | d2 | fishmv | DX-Form |
| NN | 10 011 | Rc | svstep | SVL-Form | ||||
| NN | 11 011 | Rc | setvl | SVL-Form | ||||
| NN | ---- 110 | 1/2 ops | other table [1] | |||||
| NN | RT | RA | RB | RC | 11 110 | Rc | bmrev | VA2-Form |
| NN | RT | RA | RB | sh0-4 | sh5 1 111 | Rc | bmrevi | MDS-Form |
[1] except bmrev
ops (note that av avg and abs as well as vec scalar mask are included here vector ops, and the av opcodes)
| 0.5 | 6.10 | 11.15 | 16.20 | 21 | 22.23 | 24....30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|---|
| NN | RS | me | sh | SH | ME 0 | nn00 110 | Rc | bmopsi | BM-Form |
| NN | RS | RA | sh | SH | 0 1 | nn00 110 | Rc | bmopsi | XB-Form |
| NN | RS | RA | im04 | im5 | 1 1 | im67 00 110 | Rc | bmatxori | TODO |
| NN | RT | RA | RB | 1 | 00 | 0001 110 | Rc | cldiv | X-Form |
| NN | RT | RA | RB | 1 | 01 | 0001 110 | Rc | clmod | X-Form |
| NN | RT | RA | 1 | 10 | 0001 110 | Rc | clmulh | X-Form | |
| NN | RT | RA | RB | 1 | 11 | 0001 110 | Rc | clmul | X-Form |
| NN | RT | RA | RB | 0 | 00 | 0001 110 | Rc | rsvd | |
| NN | RT | RA | RB | 0 | 01 | 0001 110 | Rc | rsvd | |
| NN | RT | RA | RB | 0 | 10 | 0001 110 | Rc | rsvd | |
| NN | RT | RA | RB | 0 | 11 | 0001 110 | Rc | vec cprop | X-Form |
| NN | 00 | 0101 110 | 0 | crfbinlog | CRB-Form | ||||
| NN | BT | BA | BFB// | 0 | 00 | 0101 110 | 1 | crbinlog | X-Form |
| NN | 1 | 00 | 0101 110 | 1 | rsvd | ||||
| NN | 10 | 0101 110 | Rc | rsvd | |||||
| NN | RT | RA | RB | sm0 | sm1 1 | 0101 110 | Rc | shaddw | X-Form |
| NN | 0 | 1001 110 | Rc | rsvd | |||||
| NN | RT | RA | RB | 1 | 00 | 1001 110 | Rc | av abss | X-Form |
| NN | RT | RA | RB | 1 | 01 | 1001 110 | Rc | av absu | X-Form |
| NN | RT | RA | RB | 1 | 10 | 1001 110 | Rc | av avgadd | X-Form |
| NN | RT | RA | RB | 1 | 11 | 1001 110 | Rc | grevlutr | X-Form |
| NN | RT | RA | RB | sm0 | sm1 0 | 1101 110 | Rc | shadd | X-Form |
| NN | RT | RA | RB | sm0 | sm1 1 | 1101 110 | Rc | shadduw | X-Form |
| NN | RT | RA | RB | 0 | 00 | 0010 110 | Rc | rsvd | |
| NN | RS | RA | sh | SH | 00 | 1010 110 | Rc | rsvd | |
| NN | RT | RA | RB | 0 | 00 | 0110 110 | Rc | rsvd | |
| NN | RS | RA | SH | 0 | 00 | 1110 110 | Rc | rsvd | |
| NN | RT | RA | RB | 1 | 00 | 1110 110 | Rc | absds | X-Form |
| NN | RT | RA | RB | 0 | 01 | 0010 110 | Rc | rsvd | |
| NN | RT | RA | RB | 1 | 01 | 0010 110 | Rc | clmulr | X-Form |
| NN | RS | RA | sh | SH | 01 | 1010 110 | Rc | rsvd | |
| NN | RT | RA | RB | 0 | 01 | 0110 110 | Rc | rsvd | |
| NN | RS | RA | SH | 0 | 01 | 1110 110 | Rc | rsvd | |
| NN | RT | RA | RB | 1 | 01 | 1110 110 | Rc | absdu | X-Form |
| NN | RS | RA | RB | 0 | 10 | 0010 110 | Rc | bmator | X-Form |
| NN | RS | RA | RB | 0 | 10 | 0110 110 | Rc | bmatand | X-Form |
| NN | RS | RA | RB | 0 | 10 | 1010 110 | Rc | bmatxor | X-Form |
| NN | RS | RA | 0 | 10 | 1110 110 | bmatflip | X-Form | ||
| NN | RT | RA | RB | 1 | 10 | 0010 110 | Rc | xpermn | X-Form |
| NN | RT | RA | RB | 1 | 10 | 0110 110 | Rc | xpermb | X-Form |
| NN | RT | RA | RB | 1 | 10 | 1010 110 | Rc | xpermh | X-Form |
| NN | RT | RA | RB | 1 | 10 | 1110 110 | Rc | xpermw | X-Form |
| NN | RT | RA | RB | 0 | 11 | 1110 110 | Rc | absdacs | X-Form |
| NN | RT | RA | RB | 1 | 11 | 1110 110 | Rc | absdacu | X-Form |
| NN | --11 110 | Rc | bmrev | VA2-Form |
binary and ternary bitops
Similar to FPGA LUTs: for two (binary) or three (ternary) inputs take bits from each input, concatenate them and perform a lookup into a table using an 8-8-bit immediate (for the ternary instructions), or in another register (4-bit for the binary instructions). The binary lookup instructions have CR Field lookup variants due to CR Fields being 4 bit.
Like the x86 AVX512F vpternlogd/vpternlogq instructions.
ternlogi
| 0.5 | 6.10 | 11.15 | 16.20 | 21..28 | 29.30 | 31 |
|---|---|---|---|---|---|---|
| NN | RT | RA | RB | im0-7 | 00 | Rc |
lut3(imm, a, b, c):
idx = c << 2 | b << 1 | a
return imm[idx] # idx by LSB0 order
for i in range(64):
RT[i] = lut3(imm, RB[i], RA[i], RT[i])
binlut
Binary lookup is a dynamic LUT2 version of ternlogi. Firstly, the lookup table is 4 bits wide not 8 bits, and secondly the lookup table comes from a register not an immediate.
| 0.5 | 6.10 | 11.15 | 16.20 | 21..25 | 26..31 | Form |
|---|---|---|---|---|---|---|
| NN | RT | RA | RB | RC | nh 00001 | VA-Form |
| NN | RT | RA | RB | /BFA/ | 0 01001 | VA-Form |
For binlut, the 4-bit LUT may be selected from either the high nibble or the low nibble of the first byte of RC:
lut2(imm, a, b):
idx = b << 1 | a
return imm[idx] # idx by LSB0 order
imm = (RC>>(nh*4))&0b1111
for i in range(64):
RT[i] = lut2(imm, RB[i], RA[i])
For bincrlut, BFA selects the 4-bit CR Field as the LUT2:
for i in range(64):
RT[i] = lut2(CRs{BFA}, RB[i], RA[i])
When Vectorized with SVP64, as usual both source and destination may be Vector or Scalar.
Programmer's note: a dynamic ternary lookup may be synthesised from
a pair of binlut instructions followed by a ternlogi to select which
to merge. Use nh to select which nibble to use as the lookup table
from the RC source register (nh=1 nibble high), i.e. keeping
an 8-bit LUT3 in RC, the first binlut instruction may set nh=0 and
the second nh=1.
crternlogi
another mode selection would be CRs not Ints.
CRB-Form:
| 0.5 | 6.8 | 9.10 | 11.13 | 14.15 | 16.18 | 19.25 | 26.30 | 31 |
|---|---|---|---|---|---|---|---|---|
| NN | BF | msk | BFA | msk | BFB | TLI | XO | TLI |
for i in range(4):
a,b,c = CRs[BF][i], CRs[BFA][i], CRs[BFB][i])
if msk[i] CRs[BF][i] = lut3(imm, a, b, c)
This instruction is remarkably similar to the existing crops, crand etc.
which have been noted to be a 4-bit (binary) LUT. In effect crternlogi
is the ternary LUT version of crops, having an 8-bit LUT. However it
is an overwrite instruction in order to save on register file ports,
due to the mask requiring the contents of the BF to be both read and
written.
Programmer's note: This instruction is useful when combined with Matrix REMAP in "Inner Product" Mode, creating Warshall Transitive Closure that has many applications in Computer Science.
crbinlog
With ternary (LUT3) dynamic instructions being very costly, and CR Fields being only 4 bit, a binary (LUT2) variant is better
CRB-Form:
| 0.5 | 6.8 | 9.10 | 11.13 | 14.15 | 16.18 | 19.25 | 26.30 | 31 |
|---|---|---|---|---|---|---|---|---|
| NN | BF | msk | BFA | msk | BFB | // | XO | // |
for i in range(4):
a,b = CRs[BF][i], CRs[BF][i])
if msk[i] CRs[BF][i] = lut2(CRs[BFB], a, b)
When SVP64 Vectorized any of the 4 operands may be Scalar or
Vector, including BFB meaning that multiple different dynamic
lookups may be performed with a single instruction. Note that
this instruction is deliberately an overwrite in order to reduce
the number of register file ports required: like crternlogi
the contents of BF must be read due to the mask only
writing back to non-masked-out bits of BF.
Programmer's note: just as with binlut and ternlogi, a pair of crbinlog instructions followed by a merging crternlogi may be deployed to synthesise dynamic ternary (LUT3) CR Field manipulation
int ops
min/m
required for the av opcodes
signed and unsigned min/max for integer.
signed/unsigned min/max gives more flexibility.
[un]signed min/max instructions are specifically needed for vector reduce min/max operations which are pretty common.
X-Form
- PO=19, XO=----000011
minmax RT, RA, RB, MMM - PO=19, XO=----000011
minmax. RT, RA, RB, MMM
see ls013 for MMM definition and pseudo-code.
implements all of (and more):
uint_xlen_t mins(uint_xlen_t rs1, uint_xlen_t rs2)
{ return (int_xlen_t)rs1 < (int_xlen_t)rs2 ? rs1 : rs2;
}
uint_xlen_t maxs(uint_xlen_t rs1, uint_xlen_t rs2)
{ return (int_xlen_t)rs1 > (int_xlen_t)rs2 ? rs1 : rs2;
}
uint_xlen_t minu(uint_xlen_t rs1, uint_xlen_t rs2)
{ return rs1 < rs2 ? rs1 : rs2;
}
uint_xlen_t maxu(uint_xlen_t rs1, uint_xlen_t rs2)
{ return rs1 > rs2 ? rs1 : rs2;
}
average
required for the av opcodes, these exist in Packed SIMD (VSX) but not scalar
uint_xlen_t intavg(uint_xlen_t rs1, uint_xlen_t rs2) {
return (rs1 + rs2 + 1) >> 1:
}
absdu
required for the av opcodes, these exist in Packed SIMD (VSX) but not scalar
uint_xlen_t absdu(uint_xlen_t rs1, uint_xlen_t rs2) {
return (src1 > src2) ? (src1-src2) : (src2-src1)
}
abs-accumulate
required for the av opcodes, these are needed for motion estimation. both are overwrite on RS.
uint_xlen_t uintabsacc(uint_xlen_t rs, uint_xlen_t ra, uint_xlen_t rb) {
return rs + (src1 > src2) ? (src1-src2) : (src2-src1)
}
uint_xlen_t intabsacc(uint_xlen_t rs, int_xlen_t ra, int_xlen_t rb) {
return rs + (src1 > src2) ? (src1-src2) : (src2-src1)
}
For SVP64, the twin Elwidths allows e.g. a 16 bit accumulator for 8 bit
differences. Form is RM-1P-3S1D where RS-as-source has a separate
SVP64 designation from RS-as-dest. This gives a limited range of
non-overwrite capability.
shift-and-add
Power ISA is missing LD/ST with shift, which is present in both ARM and x86. Too complex to add more LD/ST, a compromise is to add shift-and-add. Replaces a pair of explicit instructions in hot-loops.
# 1.6.27 Z23-FORM
|0 |6 |11 |15 |16 |21 |23 |31 |
| PO | RT | RA | RB |sm | XO |Rc |
Pseudo-code (shadd):
n <- (RB)
m <- sm + 1
RT <- (n[m:XLEN-1] || [0]*m) + (RA)
Pseudo-code (shaddw):
shift <- sm + 1 # Shift is between 1-4
n <- EXTS((RB)[XLEN/2:XLEN-1]) # Only use lower XLEN/2-bits of RB
RT <- (n << shift) + (RA) # Shift n, add RA
Pseudo-code (shadduw):
n <- ([0]*(XLEN/2)) || (RB)[XLEN/2:XLEN-1]
m <- sm + 1
RT <- (n[m:XLEN-1] || [0]*m) + (RA)
uint_xlen_t shadd(uint_xlen_t RA, uint_xlen_t RB, uint8_t sm) {
sm = sm & 0x3;
return (RB << (sm+1)) + RA;
}
uint_xlen_t shaddw(uint_xlen_t RA, uint_xlen_t RB, uint8_t sm) {
uint_xlen_t n = (int_xlen_t)(RB << XLEN / 2) >> XLEN / 2;
sm = sm & 0x3;
return (n << (sm+1)) + RA;
}
uint_xlen_t shadduw(uint_xlen_t RA, uint_xlen_t RB, uint8_t sm) {
uint_xlen_t n = RB & 0xFFFFFFFF;
sm = sm & 0x3;
return (n << (sm+1)) + RA;
}
bitmask set
based on RV bitmanip singlebit set, instruction format similar to shift fixedshift. bmext is actually covered already (shift-with-mask rldicl but only immediate version). however bitmask-invert is not, and set/clr are not covered, although they can use the same Shift ALU.
bmext (RB) version is not the same as rldicl because bmext is a right shift by RC, where rldicl is a left rotate. for the immediate version this does not matter, so a bmexti is not required. bmrev however there is no direct equivalent and consequently a bmrevi is required.
bmset (register for mask amount) is particularly useful for creating predicate masks where the length is a dynamic runtime quantity. bmset(RA=0, RB=0, RC=mask) will produce a run of ones of length "mask" in a single instruction without needing to initialise or depend on any other registers.
| 0.5 | 6.10 | 11.15 | 16.20 | 21.25 | 26..30 | 31 | name |
|---|---|---|---|---|---|---|---|
| NN | RS | RA | RB | RC | mode 010 | Rc | bm* |
Immediate-variant is an overwrite form:
| 0.5 | 6.10 | 11.15 | 16.20 | 21 | 22.23 | 24....30 | 31 | name |
|---|---|---|---|---|---|---|---|---|
| NN | RS | RB | sh | SH | itype | 1000 110 | Rc | bm*i |
def MASK(x, y):
if x < y:
x = x+1
mask_a = ((1 << x) - 1) & ((1 << 64) - 1)
mask_b = ((1 << y) - 1) & ((1 << 64) - 1)
elif x == y:
return 1 << x
else:
x = x+1
mask_a = ((1 << x) - 1) & ((1 << 64) - 1)
mask_b = (~((1 << y) - 1)) & ((1 << 64) - 1)
return mask_a ^ mask_b
uint_xlen_t bmset(RS, RB, sh)
{
int shamt = RB & (XLEN - 1);
mask = (2<<sh)-1;
return RS | (mask << shamt);
}
uint_xlen_t bmclr(RS, RB, sh)
{
int shamt = RB & (XLEN - 1);
mask = (2<<sh)-1;
return RS & ~(mask << shamt);
}
uint_xlen_t bminv(RS, RB, sh)
{
int shamt = RB & (XLEN - 1);
mask = (2<<sh)-1;
return RS ^ (mask << shamt);
}
uint_xlen_t bmext(RS, RB, sh)
{
int shamt = RB & (XLEN - 1);
mask = (2<<sh)-1;
return mask & (RS >> shamt);
}
bitmask extract with reverse. can be done by bit-order-inverting all of RB and getting bits of RB from the opposite end.
when RA is zero, no shift occurs. this makes bmextrev useful for simply reversing all bits of a register.
msb = ra[5:0];
rev[0:msb] = rb[msb:0];
rt = ZE(rev[msb:0]);
uint_xlen_t bmrevi(RA, RB, sh)
{
int shamt = XLEN-1;
if (RA != 0) shamt = (GPR(RA) & (XLEN - 1));
shamt = (XLEN-1)-shamt; # shift other end
brb = bitreverse(GPR(RB)) # swap LSB-MSB
mask = (2<<sh)-1;
return mask & (brb >> shamt);
}
uint_xlen_t bmrev(RA, RB, RC) {
return bmrevi(RA, RB, GPR(RC) & 0b111111);
}
| 0.5 | 6.10 | 11.15 | 16.20 | 21.26 | 27..30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|
| NN | RT | RA | RB | sh | 1111 | Rc | bmrevi | MDS-Form |
| 0.5 | 6.10 | 11.15 | 16.20 | 21.25 | 26..30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|
| NN | RT | RA | RB | RC | 11110 | Rc | bmrev | VA2-Form |
grevlut
generalised reverse combined with a pair of LUT2s and allowing
a constant 0b0101...0101 when RA=0, and an option to invert
(including when RA=0, giving a constant 0b1010...1010 as the
initial value) provides a wide range of instructions
and a means to set hundreds of regular 64 bit patterns with one
single 32 bit instruction.
the two LUT2s are applied left-half (when not swapping) and right-half (when swapping) so as to allow a wider range of options.
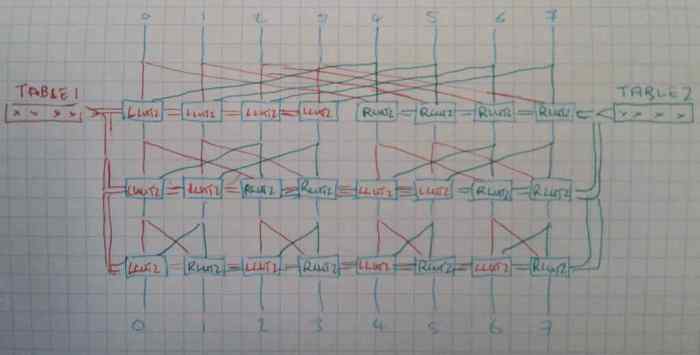
- A value of
0b11001010for the immediate provides the functionality of a standard "grev". 0b11101110provides gorc
grevlut should be arranged so as to produce the constants needed to put into bext (bitextract) so as in turn to be able to emulate x86 pmovmask instructions https://www.felixcloutier.com/x86/pmovmskb. This only requires 2 instructions (grevlut, bext).
Note that if the mask is required to be placed
directly into CR Fields (for use as CR Predicate
masks rather than a integer mask) then sv.cmpi or sv.ori
may be used instead, bearing in mind that sv.ori
is a 64-bit instruction, and VL must have been
set to the required length:
sv.ori./elwid=8 r10.v, r10.v, 0
The following settings provide the required mask constants:
| RA=0 | RB | imm | iv | result |
|---|---|---|---|---|
| 0x555.. | 0b10 | 0b01101100 | 0 | 0x111111... |
| 0x555.. | 0b110 | 0b01101100 | 0 | 0x010101... |
| 0x555.. | 0b1110 | 0b01101100 | 0 | 0x00010001... |
| 0x555.. | 0b10 | 0b11000110 | 1 | 0x88888... |
| 0x555.. | 0b110 | 0b11000110 | 1 | 0x808080... |
| 0x555.. | 0b1110 | 0b11000110 | 1 | 0x80008000... |
Better diagram showing the correct ordering of shamt (RB). A LUT2 is applied to all locations marked in red using the first 4 bits of the immediate, and a separate LUT2 applied to all locations in green using the upper 4 bits of the immediate.

demo code grevlut.py
def lut2(imm, a, b):
idx = b << 1 | a
return (imm>>idx) & 1
def dorow(imm8, step_i, chunk_size):
step_o = 0
for j in range(64):
if (j&chunk_size) == 0:
imm = (imm8 & 0b1111)
else:
imm = (imm8>>4)
a = (step_i>>j)&1
b = (step_i>>(j ^ chunk_size))&1
res = lut2(imm, a, b)
#print(j, bin(imm), a, b, res)
step_o |= (res<<j)
#print (" ", chunk_size, bin(step_o))
return step_o
def grevlut64(RA, RB, imm, iv):
x = 0
if RA is None: # RA=0
x = 0x5555555555555555
else:
x = RA
if (iv): x = ~x;
shamt = RB & 63;
for i in range(6):
step = 1<<i
if (shamt & step):
x = dorow(imm, x, step)
return x & ((1<<64)-1)
A variant may specify different LUT-pairs per row,
using one byte of RB for each. If it is desired that
a particular row-crossover shall not be applied it is
a simple matter to set the appropriate LUT-pair in RB
to effect an identity transform for that row (0b11001010).
uint64_t grevlutr(uint64_t RA, uint64_t RB, bool iv, bool is32b)
{
uint64_t x = 0x5555_5555_5555_5555;
if (RA != 0) x = GPR(RA);
if (iv) x = ~x;
for i in 0 to (6-is32b)
step = 1<<i
imm = (RB>>(i*8))&0xff
x = dorow(imm, x, step, is32b)
return x;
}
| 0.5 | 6.10 | 11.15 | 16.20 | 21..28 | 29.30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|
| NN | RT | RA | s0-4 | im0-7 | 1 iv | s5 | grevlogi | |
| NN | RT | RA | RB | im0-7 | 01 | 0 | grevlog |
An equivalent to grevlogw may be synthesised by setting the
appropriate bits in RB to set the top half of RT to zero.
Thus an explicit grevlogw instruction is not necessary.
xperm
based on RV bitmanip.
RA contains a vector of indices to select parts of RB to be copied to RT. The immediate-variant allows up to an 8 bit pattern (repeated) to be targetted at different parts of RT.
xperm shares some similarity with one of the uses of bmator in that xperm indices are binary addressing where bitmator may be considered to be unary addressing.
uint_xlen_t xpermi(uint8_t imm8, uint_xlen_t RB, int sz_log2)
{
uint_xlen_t r = 0;
uint_xlen_t sz = 1LL << sz_log2;
uint_xlen_t mask = (1LL << sz) - 1;
uint_xlen_t RA = imm8 | imm8<<8 | ... | imm8<<56;
for (int i = 0; i < XLEN; i += sz) {
uint_xlen_t pos = ((RA >> i) & mask) << sz_log2;
if (pos < XLEN)
r |= ((RB >> pos) & mask) << i;
}
return r;
}
uint_xlen_t xperm(uint_xlen_t RA, uint_xlen_t RB, int sz_log2)
{
uint_xlen_t r = 0;
uint_xlen_t sz = 1LL << sz_log2;
uint_xlen_t mask = (1LL << sz) - 1;
for (int i = 0; i < XLEN; i += sz) {
uint_xlen_t pos = ((RA >> i) & mask) << sz_log2;
if (pos < XLEN)
r |= ((RB >> pos) & mask) << i;
}
return r;
}
uint_xlen_t xperm_n (uint_xlen_t RA, uint_xlen_t RB)
{ return xperm(RA, RB, 2); }
uint_xlen_t xperm_b (uint_xlen_t RA, uint_xlen_t RB)
{ return xperm(RA, RB, 3); }
uint_xlen_t xperm_h (uint_xlen_t RA, uint_xlen_t RB)
{ return xperm(RA, RB, 4); }
uint_xlen_t xperm_w (uint_xlen_t RA, uint_xlen_t RB)
{ return xperm(RA, RB, 5); }
bitmatrix
bmatflip and bmatxor is found in the Cray XMT, and in x86 is known as GF2P8AFFINEQB. uses:
- https://gist.github.com/animetosho/d3ca95da2131b5813e16b5bb1b137ca0
- SM4, Reed Solomon, RAID6 https://stackoverflow.com/questions/59124720/what-are-the-avx-512-galois-field-related-instructions-for
- Vector bit-reverse https://reviews.llvm.org/D91515?id=305411
- Affine Inverse https://github.com/HJLebbink/asm-dude/wiki/GF2P8AFFINEINVQB
| 0.5 | 6.10 | 11.15 | 16.20 | 21 | 22.23 | 24....30 | 31 | name | Form |
|---|---|---|---|---|---|---|---|---|---|
| NN | RS | RA | im04 | im5 | 1 1 | im67 00 110 | Rc | bmatxori | TODO |
uint64_t bmatflip(uint64_t RA)
{
uint64_t x = RA;
x = shfl64(x, 31);
x = shfl64(x, 31);
x = shfl64(x, 31);
return x;
}
uint64_t bmatxori(uint64_t RS, uint64_t RA, uint8_t imm) {
// transpose of RA
uint64_t RAt = bmatflip(RA);
uint8_t u[8]; // rows of RS
uint8_t v[8]; // cols of RA
for (int i = 0; i < 8; i++) {
u[i] = RS >> (i*8);
v[i] = RAt >> (i*8);
}
uint64_t bit, x = 0;
for (int i = 0; i < 64; i++) {
bit = (imm >> (i%8)) & 1;
bit ^= pcnt(u[i / 8] & v[i % 8]) & 1;
x |= bit << i;
}
return x;
}
uint64_t bmatxor(uint64_t RA, uint64_t RB) {
return bmatxori(RA, RB, 0xff)
}
uint64_t bmator(uint64_t RA, uint64_t RB) {
// transpose of RB
uint64_t RBt = bmatflip(RB);
uint8_t u[8]; // rows of RA
uint8_t v[8]; // cols of RB
for (int i = 0; i < 8; i++) {
u[i] = RA >> (i*8);
v[i] = RBt >> (i*8);
}
uint64_t x = 0;
for (int i = 0; i < 64; i++) {
if ((u[i / 8] & v[i % 8]) != 0)
x |= 1LL << i;
}
return x;
}
uint64_t bmatand(uint64_t RA, uint64_t RB) {
// transpose of RB
uint64_t RBt = bmatflip(RB);
uint8_t u[8]; // rows of RA
uint8_t v[8]; // cols of RB
for (int i = 0; i < 8; i++) {
u[i] = RA >> (i*8);
v[i] = RBt >> (i*8);
}
uint64_t x = 0;
for (int i = 0; i < 64; i++) {
if ((u[i / 8] & v[i % 8]) == 0xff)
x |= 1LL << i;
}
return x;
}
Introduction to Carry-less and GF arithmetic
- obligatory xkcd https://xkcd.com/2595/
There are three completely separate types of Galois-Field-based arithmetic that we implement which are not well explained even in introductory literature. A slightly oversimplified explanation is followed by more accurate descriptions:
GF(2)carry-less binary arithmetic. this is not actually a Galois Field, but is accidentally referred to as GF(2) - see below as to why.GF(p)modulo arithmetic with a Prime number, these are "proper" Galois FieldsGF(2^N)carry-less binary arithmetic with two limits: modulo a power-of-2 (2N) and a second "reducing" polynomial (similar to a prime number), these are said to be GF(2N) arithmetic.
further detailed and more precise explanations are provided below
- Polynomials with coefficients in
GF(2)(aka. Carry-less arithmetic -- thecl*instructions). This isn't actually a Galois Field, but its coefficients are. This is basically binary integer addition, subtraction, and multiplication like usual, except that carries aren't propagated at all, effectively turning both addition and subtraction into the bitwise xor operation. Division and remainder are defined to match how addition and multiplication works. - Galois Fields with a prime size
(aka.
GF(p)or Prime Galois Fields -- thegfp*instructions). This is basically just the integers modp. - Galois Fields with a power-of-a-prime size
(aka.
GF(p^n)orGF(q)whereq == p^nfor primepand integern > 0). We only implement these forp == 2, called Binary Galois Fields (GF(2^n)-- thegfb*instructions). For any primep,GF(p^n)is implemented as polynomials with coefficients inGF(p)and degree< n, where the polynomials are the remainders of dividing by a specificly chosen polynomial inGF(p)called the Reducing Polynomial (we will denote that byred_poly). The Reducing Polynomial must be an irreducable polynomial (like primes, but for polynomials), as well as have degreen. AllGF(p^n)for the samepandnare isomorphic to each other -- the choice ofred_polydoesn't affectGF(p^n)'s mathematical shape, all that changes is the specific polynomials used to implementGF(p^n).
Many implementations and much of the literature do not make a clear distinction between these three categories, which makes it confusing to understand what their purpose and value is.
- carry-less multiply is extremely common and is used for the ubiquitous CRC32 algorithm. [TODO add many others, helps justify to ISA WG]
- GF(2N) forms the basis of Rijndael (the current AES standard) and has significant uses throughout cryptography
- GF(p) is the basis again of a significant quantity of algorithms (TODO, list them, jacob knows what they are), even though the modulo is limited to be below 64-bit (size of a scalar int)
Instructions for Carry-less Operations
aka. Polynomials with coefficients in GF(2)
Carry-less addition/subtraction is simply XOR, so a cladd
instruction is not provided since the xor[i] instruction can be used instead.
These are operations on polynomials with coefficients in GF(2), with the
polynomial's coefficients packed into integers with the following algorithm:
Carry-less Multiply Instructions
based on RV bitmanip see https://en.wikipedia.org/wiki/CLMUL_instruction_set and https://www.felixcloutier.com/x86/pclmulqdq and https://en.m.wikipedia.org/wiki/Carry-less_product
They are worth adding as their own non-overwrite operations (in the same pipeline).
clmul Carry-less Multiply
clmulh Carry-less Multiply High
clmulr Carry-less Multiply (Reversed)
Useful for CRCs. Equivalent to bit-reversing the result of clmul on
bit-reversed inputs.
clmadd Carry-less Multiply-Add
clmadd RT, RA, RB, RC
(RT) = clmul((RA), (RB)) ^ (RC)
cltmadd Twin Carry-less Multiply-Add (for FFTs)
Used in combination with SV FFT REMAP to perform a full Discrete Fourier Transform of Polynomials over GF(2) in-place. Possible by having 3-in 2-out, to avoid the need for a temp register. RS is written to as well as RT.
Note: Polynomials over GF(2) are a Ring rather than a Field, so, because the definition of the Inverse Discrete Fourier Transform involves calculating a multiplicative inverse, which may not exist in every Ring, therefore the Inverse Discrete Fourier Transform may not exist. (AFAICT the number of inputs to the IDFT must be odd for the IDFT to be defined for Polynomials over GF(2). TODO: check with someone who knows for sure if that's correct.)
cltmadd RT, RA, RB, RC
TODO: add link to explanation for where RS comes from.
a = (RA)
c = (RC)
# read all inputs before writing to any outputs in case
# an input overlaps with an output register.
(RT) = clmul(a, (RB)) ^ c
(RS) = a ^ c
cldivrem Carry-less Division and Remainder
cldivrem isn't an actual instruction, but is just used in the pseudo-code
for other instructions.
cldiv Carry-less Division
cldiv RT, RA, RB
n = (RA)
d = (RB)
q, r = cldivrem(n, d, width=XLEN)
(RT) = q
clrem Carry-less Remainder
clrem RT, RA, RB
n = (RA)
d = (RB)
q, r = cldivrem(n, d, width=XLEN)
(RT) = r
Instructions for Binary Galois Fields GF(2^m)
see:
- https://courses.csail.mit.edu/6.857/2016/files/ffield.py
- https://engineering.purdue.edu/kak/compsec/NewLectures/Lecture7.pdf
- https://foss.heptapod.net/math/libgf2/-/blob/branch/default/src/libgf2/gf2.py
Binary Galois Field addition/subtraction is simply XOR, so a gfbadd
instruction is not provided since the xor[i] instruction can be used instead.
GFBREDPOLY SPR -- Reducing Polynomial
In order to save registers and to make operations orthogonal with standard
arithmetic, the reducing polynomial is stored in a dedicated SPR GFBREDPOLY.
This also allows hardware to pre-compute useful parameters (such as the
degree, or look-up tables) based on the reducing polynomial, and store them
alongside the SPR in hidden registers, only recomputing them whenever the SPR
is written to, rather than having to recompute those values for every
instruction.
Because Galois Fields require the reducing polynomial to be an irreducible
polynomial, that guarantees that any polynomial of degree > 1 must have
the LSB set, since otherwise it would be divisible by the polynomial x,
making it reducible, making whatever we're working on no longer a Field.
Therefore, we can reuse the LSB to indicate degree == XLEN.
gfbredpoly -- Set the Reducing Polynomial SPR GFBREDPOLY
unless this is an immediate op, mtspr is completely sufficient.
gfbmul -- Binary Galois Field GF(2^m) Multiplication
gfbmul RT, RA, RB
gfbmadd -- Binary Galois Field GF(2^m) Multiply-Add
gfbmadd RT, RA, RB, RC
the main entry point for our hardware implementation of both gfbmul and gfbmadd can be found at:
nmigen-gf.git/src/nmigen_gf/hdl/gfbmadd.py:419
gfbtmadd -- Binary Galois Field GF(2^m) Twin Multiply-Add (for FFT)
Used in combination with SV FFT REMAP to perform a full GF(2^m) Discrete
Fourier Transform in-place. Possible by having 3-in 2-out, to avoid the need
for a temp register. RS is written to as well as RT.
gfbtmadd RT, RA, RB, RC
TODO: add link to explanation for where RS comes from.
a = (RA)
c = (RC)
# read all inputs before writing to any outputs in case
# an input overlaps with an output register.
(RT) = gfbmadd(a, (RB), c)
# use gfbmadd again since it reduces the result
(RS) = gfbmadd(a, 1, c) # "a * 1 + c"
gfbinv -- Binary Galois Field GF(2^m) Inverse
gfbinv RT, RA
The main entry point in our hardware implementation can be found at:
nmigen-gf.git/src/nmigen_gf/hdl/gfbinv.py:386
Instructions for Prime Galois Fields GF(p)
GFPRIME SPR -- Prime Modulus For gfp* Instructions
gfpadd Prime Galois Field GF(p) Addition
gfpadd RT, RA, RB
the addition happens on infinite-precision integers
gfpsub Prime Galois Field GF(p) Subtraction
gfpsub RT, RA, RB
the subtraction happens on infinite-precision integers
gfpmul Prime Galois Field GF(p) Multiplication
gfpmul RT, RA, RB
the multiplication happens on infinite-precision integers
gfpinv Prime Galois Field GF(p) Invert
gfpinv RT, RA
Some potential hardware implementations are found in: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.90.5233&rep=rep1&type=pdf
gfpmadd Prime Galois Field GF(p) Multiply-Add
gfpmadd RT, RA, RB, RC
the multiplication and addition happens on infinite-precision integers
gfpmsub Prime Galois Field GF(p) Multiply-Subtract
gfpmsub RT, RA, RB, RC
the multiplication and subtraction happens on infinite-precision integers
gfpmsubr Prime Galois Field GF(p) Multiply-Subtract-Reversed
gfpmsubr RT, RA, RB, RC
the multiplication and subtraction happens on infinite-precision integers
gfpmaddsubr Prime Galois Field GF(p) Multiply-Add and Multiply-Sub-Reversed (for FFT)
Used in combination with SV FFT REMAP to perform a full Number-Theoretic-Transform in-place. Possible by having 3-in 2-out, to avoid the need for a temp register. RS is written to as well as RT.
gfpmaddsubr RT, RA, RB, RC
TODO: add link to explanation for where RS comes from.
factor1 = (RA)
factor2 = (RB)
term = (RC)
# read all inputs before writing to any outputs in case
# an input overlaps with an output register.
(RT) = gfpmadd(factor1, factor2, term)
(RS) = gfpmsubr(factor1, factor2, term)
Already in POWER ISA or subsumed
Lists operations either included as part of other bitmanip operations, or are already in Power ISA.
cmix
based on RV bitmanip, covered by ternlog bitops
uint_xlen_t cmix(uint_xlen_t RA, uint_xlen_t RB, uint_xlen_t RC) {
return (RA & RB) | (RC & ~RB);
}
count leading/trailing zeros with mask
in v3.1 p105
count = 0
do i = 0 to 63 if((RB)i=1) then do
if((RS)i=1) then break end end count ← count + 1
RA ← EXTZ64(count)
bit deposit
pdepd VRT,VRA,VRB, identical to RV bitmamip bdep, found already in v3.1 p106
do while(m < 64)
if VSR[VRB+32].dword[i].bit[63-m]=1 then do
result = VSR[VRA+32].dword[i].bit[63-k]
VSR[VRT+32].dword[i].bit[63-m] = result
k = k + 1
m = m + 1
uint_xlen_t bdep(uint_xlen_t RA, uint_xlen_t RB)
{
uint_xlen_t r = 0;
for (int i = 0, j = 0; i < XLEN; i++)
if ((RB >> i) & 1) {
if ((RA >> j) & 1)
r |= uint_xlen_t(1) << i;
j++;
}
return r;
}
bit extract
other way round: identical to RV bext: pextd, found in v3.1 p196
uint_xlen_t bext(uint_xlen_t RA, uint_xlen_t RB)
{
uint_xlen_t r = 0;
for (int i = 0, j = 0; i < XLEN; i++)
if ((RB >> i) & 1) {
if ((RA >> i) & 1)
r |= uint_xlen_t(1) << j;
j++;
}
return r;
}
centrifuge
found in v3.1 p106 so not to be added here
ptr0 = 0
ptr1 = 0
do i = 0 to 63
if((RB)i=0) then do
resultptr0 = (RS)i
end
ptr0 = ptr0 + 1
if((RB)63-i==1) then do
result63-ptr1 = (RS)63-i
end
ptr1 = ptr1 + 1
RA = result
bit to byte permute
similar to matrix permute in RV bitmanip, which has XOR and OR variants, these perform a transpose (bmatflip). TODO this looks VSX is there a scalar variant in v3.0/1 already
do j = 0 to 7
do k = 0 to 7
b = VSR[VRB+32].dword[i].byte[k].bit[j]
VSR[VRT+32].dword[i].byte[j].bit[k] = b
grev
superceded by grevlut
based on RV bitmanip, this is also known as a butterfly network. however where a butterfly network allows setting of every crossbar setting in every row and every column, generalised-reverse (grev) only allows a per-row decision: every entry in the same row must either switch or not-switch.

uint64_t grev64(uint64_t RA, uint64_t RB)
{
uint64_t x = RA;
int shamt = RB & 63;
if (shamt & 1) x = ((x & 0x5555555555555555LL) << 1) |
((x & 0xAAAAAAAAAAAAAAAALL) >> 1);
if (shamt & 2) x = ((x & 0x3333333333333333LL) << 2) |
((x & 0xCCCCCCCCCCCCCCCCLL) >> 2);
if (shamt & 4) x = ((x & 0x0F0F0F0F0F0F0F0FLL) << 4) |
((x & 0xF0F0F0F0F0F0F0F0LL) >> 4);
if (shamt & 8) x = ((x & 0x00FF00FF00FF00FFLL) << 8) |
((x & 0xFF00FF00FF00FF00LL) >> 8);
if (shamt & 16) x = ((x & 0x0000FFFF0000FFFFLL) << 16) |
((x & 0xFFFF0000FFFF0000LL) >> 16);
if (shamt & 32) x = ((x & 0x00000000FFFFFFFFLL) << 32) |
((x & 0xFFFFFFFF00000000LL) >> 32);
return x;
}
gorc
based on RV bitmanip, gorc is superceded by grevlut
uint32_t gorc32(uint32_t RA, uint32_t RB)
{
uint32_t x = RA;
int shamt = RB & 31;
if (shamt & 1) x |= ((x & 0x55555555) << 1) | ((x & 0xAAAAAAAA) >> 1);
if (shamt & 2) x |= ((x & 0x33333333) << 2) | ((x & 0xCCCCCCCC) >> 2);
if (shamt & 4) x |= ((x & 0x0F0F0F0F) << 4) | ((x & 0xF0F0F0F0) >> 4);
if (shamt & 8) x |= ((x & 0x00FF00FF) << 8) | ((x & 0xFF00FF00) >> 8);
if (shamt & 16) x |= ((x & 0x0000FFFF) << 16) | ((x & 0xFFFF0000) >> 16);
return x;
}
uint64_t gorc64(uint64_t RA, uint64_t RB)
{
uint64_t x = RA;
int shamt = RB & 63;
if (shamt & 1) x |= ((x & 0x5555555555555555LL) << 1) |
((x & 0xAAAAAAAAAAAAAAAALL) >> 1);
if (shamt & 2) x |= ((x & 0x3333333333333333LL) << 2) |
((x & 0xCCCCCCCCCCCCCCCCLL) >> 2);
if (shamt & 4) x |= ((x & 0x0F0F0F0F0F0F0F0FLL) << 4) |
((x & 0xF0F0F0F0F0F0F0F0LL) >> 4);
if (shamt & 8) x |= ((x & 0x00FF00FF00FF00FFLL) << 8) |
((x & 0xFF00FF00FF00FF00LL) >> 8);
if (shamt & 16) x |= ((x & 0x0000FFFF0000FFFFLL) << 16) |
((x & 0xFFFF0000FFFF0000LL) >> 16);
if (shamt & 32) x |= ((x & 0x00000000FFFFFFFFLL) << 32) |
((x & 0xFFFFFFFF00000000LL) >> 32);
return x;
}
Appendix
see appendix